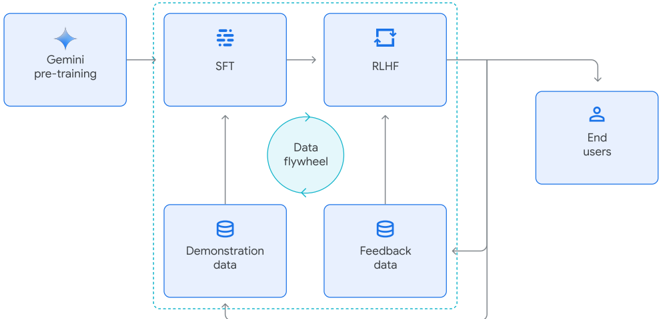
## Flowchart: Gemini Model Training and Feedback Loop
### Overview
The diagram illustrates a cyclical process for training and refining a Gemini AI model, emphasizing iterative improvement through user interaction. The core components include pre-training, supervised fine-tuning (SFT), reinforcement learning from human feedback (RLHF), and a data flywheel mechanism integrating demonstration and feedback data.
### Components/Axes
1. **Gemini pre-training**: Initial training phase (leftmost block).
2. **SFT (Supervised Fine-Tuning)**: Block with dashed lines, receives input from pre-training and demonstration data.
3. **RLHF (Reinforcement Learning from Human Feedback)**: Block with circular arrows, outputs to end users.
4. **Demonstration data**: Stacked data icon, feeds into SFT.
5. **Feedback data**: Stacked data icon, receives input from end users and outputs to SFT.
6. **End users**: Final output recipient (rightmost block).
7. **Data flywheel**: Central circular element symbolizing continuous data recycling.
### Detailed Analysis
- **Flow Direction**:
- Pre-training → SFT → RLHF → End users.
- End users → Feedback data → Demonstration data → SFT (loop closure).
- **Key Connections**:
- Feedback data merges with demonstration data to refine SFT.
- RLHF outputs directly to end users, creating a closed-loop system.
- **Visual Elements**:
- Dashed lines between SFT and RLHF suggest iterative refinement.
- Circular arrows in RLHF indicate ongoing optimization.
- Data flywheel at the center emphasizes cyclical data reuse.
### Key Observations
- **Cyclical Nature**: The system forms a closed loop, with user feedback directly influencing model improvement.
- **Data Integration**: Demonstration and feedback data are combined to enhance SFT, avoiding isolated training phases.
- **User-Centric Design**: End users are positioned as active participants, not passive recipients.
### Interpretation
This flowchart demonstrates a **human-in-the-loop AI training pipeline** where user interactions drive continuous model enhancement. The data flywheel metaphor highlights the importance of recycling real-world feedback to refine the model iteratively. By integrating demonstration data (likely curated examples) with organic user feedback, the system balances structured learning with adaptive improvement. The positioning of RLHF as the final training stage before user interaction suggests a focus on aligning outputs with human preferences before deployment. This architecture prioritizes scalability and responsiveness, enabling the model to evolve based on real-world usage patterns rather than static datasets alone.