TECHNICAL ASSET FINGERPRINT
064b1e8c600a2db158ac793c
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
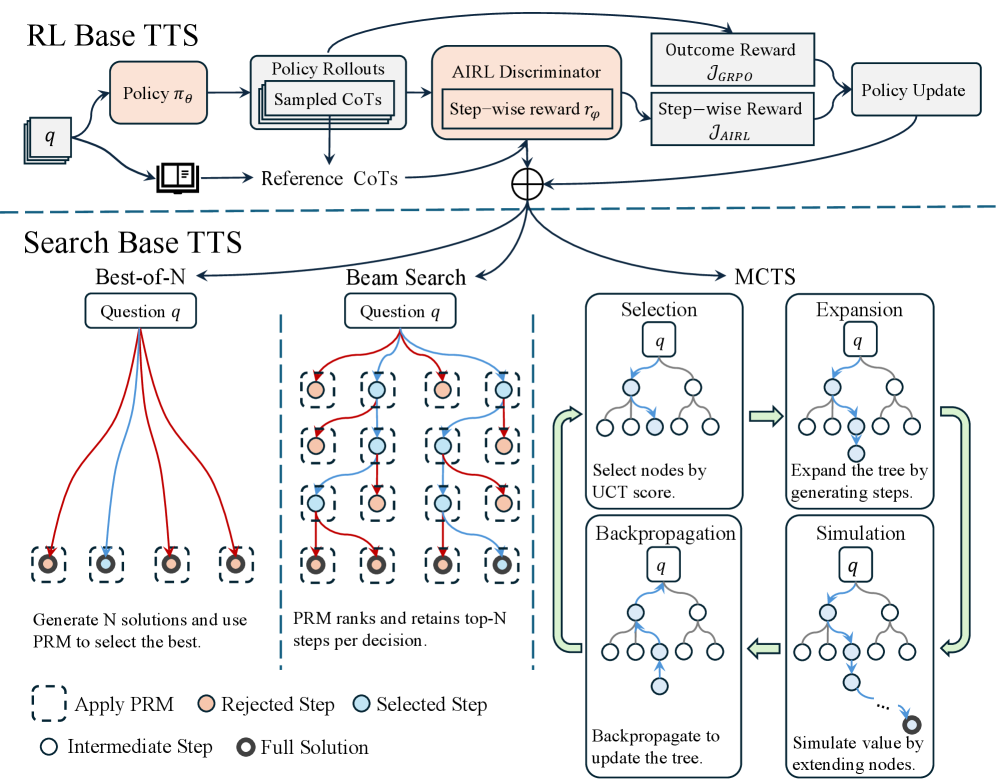
## Diagram: Comparison of RL-Based and Search-Based Test-Time Scaling (TTS) Methods
### Overview
The image is a technical diagram illustrating two distinct paradigms for Test-Time Scaling (TTS) in AI models, specifically for solving reasoning tasks (indicated by "Question q"). The top section details a Reinforcement Learning (RL) approach, while the bottom section details three Search-based approaches. The diagram uses flowcharts, tree structures, and a legend to explain the processes, components, and data flow for each method.
### Components/Axes
The diagram is divided into two primary sections by a horizontal dashed line.
**Top Section: RL Base TTS**
* **Main Flow:** `Question q` → `Policy π_θ` → `Policy Rollouts (Sampled CoTs)` → `AIRL Discriminator (Step-wise reward r_φ)` → `Outcome Reward J_GRPO` & `Step-wise Reward J_AIRL` → `Policy Update`.
* **Parallel Input:** `Question q` also leads to `Reference CoTs` (depicted as a document icon).
* **Feedback Loop:** The `Policy Update` feeds back into the `Policy π_θ`.
* **Key Labels:** `Policy π_θ`, `Policy Rollouts`, `Sampled CoTs`, `Reference CoTs`, `AIRL Discriminator`, `Step-wise reward r_φ`, `Outcome Reward J_GRPO`, `Step-wise Reward J_AIRL`, `Policy Update`.
**Bottom Section: Search Base TTS**
This section is further divided into three columns, each representing a different search strategy applied to `Question q`.
1. **Left Column: Best-of-N**
* **Process:** `Question q` branches into multiple paths (red and blue lines) leading to several `Full Solution` nodes (black circles).
* **Text Description:** "Generate N solutions and use PRM to select the best."
2. **Middle Column: Beam Search**
* **Process:** `Question q` leads to a tree structure where paths (red and blue lines) branch through multiple layers of `Intermediate Step` nodes (white circles). The tree is pruned at each level.
* **Text Description:** "PRM ranks and retains top-N steps per decision."
3. **Right Column: MCTS (Monte Carlo Tree Search)**
* **Process:** A four-phase cyclic process depicted with four sub-diagrams connected by green arrows:
* **Selection:** "Select nodes by UCT score." (Shows a tree with a path highlighted in blue).
* **Expansion:** "Expand the tree by generating steps." (Shows a new node added to the tree).
* **Simulation:** "Simulate value by extending nodes." (Shows a dotted line extending from a leaf node).
* **Backpropagation:** "Backpropagate to update the tree." (Shows arrows moving back up the tree).
* **Key Labels:** `Selection`, `Expansion`, `Simulation`, `Backpropagation`, `UCT score`.
**Legend (Bottom-Left Corner):**
* `--- Apply PRM` (Dashed box)
* `○ Rejected Step` (Orange circle)
* `○ Selected Step` (Blue circle)
* `○ Intermediate Step` (White circle)
* `● Full Solution` (Black circle)
### Detailed Analysis
**RL Base TTS Flow:**
The process begins with a question (`q`). A policy model (`π_θ`) generates multiple reasoning paths, referred to as "Sampled CoTs" (Chains of Thought), through policy rollouts. These are evaluated by an "AIRL Discriminator" which provides a step-wise reward signal (`r_φ`). This reward is used to compute two objective functions: an outcome-based reward (`J_GRPO`) and a step-wise reward (`J_AIRL`). These rewards drive a "Policy Update," creating a closed-loop learning system. A set of "Reference CoTs" is also provided as a potential input or benchmark.
**Search Base TTS Flow:**
All three methods start with the same `Question q` but employ different search algorithms to find a solution.
* **Best-of-N:** A parallel generation approach. Multiple complete solutions are generated independently. A Process Reward Model (PRM) is then applied (indicated by dashed boxes around the final nodes) to score and select the single best full solution.
* **Beam Search:** A sequential, breadth-first search with pruning. At each decision step (layer of the tree), the PRM ranks all possible next steps. Only the top-N most promising steps (blue "Selected Step" nodes) are retained for further expansion, while others (orange "Rejected Step" nodes) are discarded.
* **MCTS:** A tree search algorithm that balances exploration and exploitation. It iteratively performs four steps: 1) **Selection** of promising leaf nodes using the UCT (Upper Confidence bounds for Trees) formula, 2) **Expansion** of the tree by adding new child nodes (steps), 3) **Simulation** (or rollout) from the new node to estimate its value, and 4) **Backpropagation** of the simulation result up the tree to update node values.
### Key Observations
1. **Paradigm Contrast:** The diagram explicitly contrasts a *learning-based* approach (RL Base TTS, which updates a policy model) with *inference-time search* approaches (Search Base TTS, which uses a fixed model but searches for better outputs).
2. **Role of PRM:** The Process Reward Model (PRM) is a critical component in all three search-based methods, used for scoring and selecting steps or final solutions. Its application is visually marked by dashed boxes in the Best-of-N and Beam Search diagrams.
3. **Granularity of Reward:** The RL method uses both outcome-level (`J_GRPO`) and step-level (`J_AIRL`) rewards. The search methods inherently operate at a step-level granularity through their ranking and selection mechanisms.
4. **Visual Coding:** The legend is essential for interpreting the search diagrams. Blue lines/nodes represent the selected, high-reward path, while red lines/orange nodes represent rejected or lower-reward paths. The flow of the MCTS cycle is clearly indicated by large green arrows.
### Interpretation
This diagram serves as a conceptual framework for understanding how different TTS strategies operate. It suggests that improving AI reasoning at inference time can be approached either by **training a better policy** (RL Base) that internalizes the reward signal, or by **employing a more sophisticated search** (Search Base) around a fixed policy to find optimal reasoning paths.
The **RL Base TTS** represents an "end-to-end" learning paradigm where the model's parameters are directly optimized based on reward signals derived from both the final outcome and intermediate steps. This is akin to learning a skill through practice and feedback.
The **Search Base TTS** methods represent a "plan-and-execute" paradigm. They treat the base model as a black-box function generator and use algorithmic search (Best-of-N, Beam Search, MCTS) to navigate the vast space of possible reasoning chains. The PRM acts as a heuristic guide, similar to a value function in classic search problems. MCTS is notably the most complex, incorporating elements of both exploration (trying new steps) and exploitation (refining known good paths).
The key implication is a trade-off: RL-based methods may offer faster inference once trained but require costly training and careful reward shaping. Search-based methods can be applied to any existing model without retraining but incur higher computational costs at inference time due to the search process. The diagram effectively maps out the architectural choices and core mechanisms involved in this active area of AI research.
DECODING INTELLIGENCE...