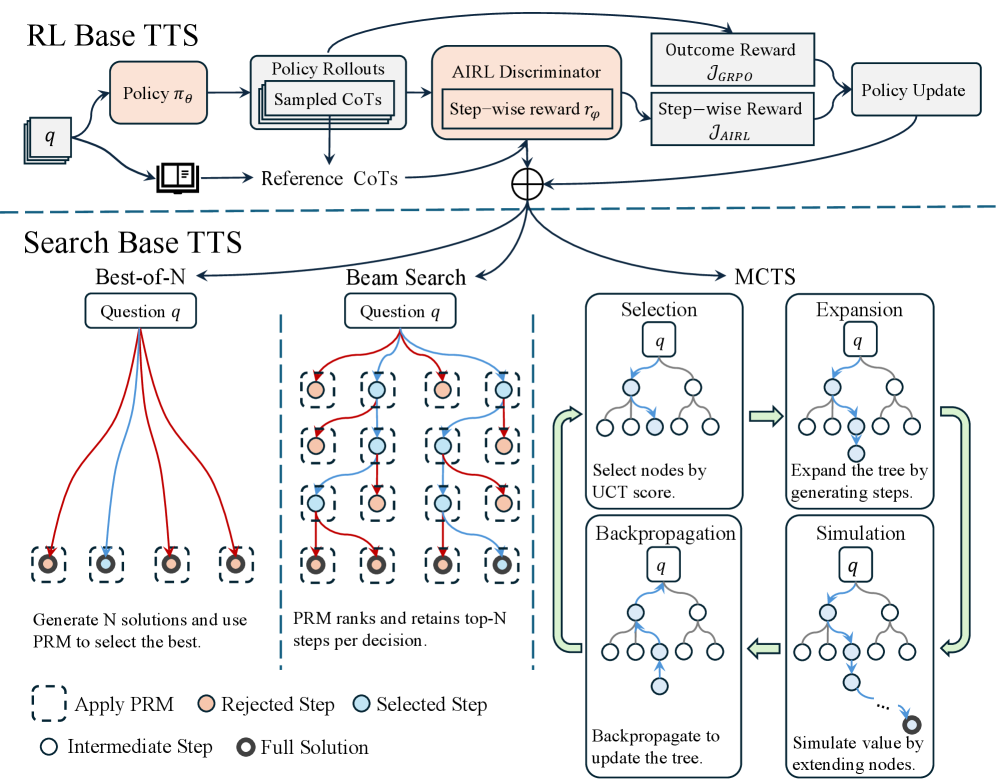
## Diagram: Technical Architecture of Tree Search Strategies (TTS) with Reinforcement Learning and Search-Based Methods
### Overview
The diagram illustrates a hybrid system combining Reinforcement Learning (RL) and search-based approaches for decision-making in a Tree Search Strategy (TTS) framework. It contrasts two primary TTS paradigms: **RL Base TTS** (policy-driven) and **Search Base TTS** (solution exploration), with a focus on their integration via Monte Carlo Tree Search (MCTS) and Proximal Policy Optimization (PRM).
---
### Components/Axes
#### RL Base TTS (Top Section)
1. **Policy πθ**: A policy network generating actions from state `q`.
2. **Policy Rollouts**: Simulated trajectories from `q` using πθ.
3. **Sampled CoTs**: Contextualized trajectories (CoTs) derived from rollouts.
4. **AIRL Discriminator**: Evaluates rollouts using a step-wise reward `rφ`.
5. **Outcome Reward (J_GRPO)**: Global reward for full solutions.
6. **Step-wise Reward (J_AIRL)**: Per-step reward for intermediate steps.
7. **Policy Update**: Feedback loop to refine πθ using rewards.
#### Search Base TTS (Bottom Section)
1. **Best-of-N**: Generates `N` candidate solutions for `q` and selects the best via PRM.
2. **Beam Search**:
- **PRM Ranking**: Retains top-N steps per decision using PRM.
- **Flow Arrows**: Red (rejected steps), Blue (selected steps).
3. **MCTS (Monte Carlo Tree Search)**:
- **Selection**: Expands nodes based on UCT scores.
- **Expansion**: Adds child nodes to the tree.
- **Backpropagation**: Updates node values using simulation results.
- **Simulation**: Estimates solution value by extending nodes.
#### Legend (Bottom)
- **Apply PRM**: Dashed square (PRM applied to steps).
- **Rejected Step**: Orange circle (discarded during PRM).
- **Selected Step**: Blue circle (retained during PRM).
- **Intermediate Step**: Gray circle (partial solution).
- **Full Solution**: Black circle (complete solution).
---
### Detailed Analysis
#### RL Base TTS Workflow
1. **Policy πθ** generates actions for state `q`, leading to **Policy Rollouts**.
2. Rollouts are sampled as **CoTs** and evaluated by the **AIRL Discriminator**, which computes:
- **Step-wise Reward (J_AIRL)**: Per-step quality.
- **Outcome Reward (J_GRPO)**: Final solution quality.
3. These rewards update **Policy πθ** via gradient ascent, refining the policy iteratively.
#### Search Base TTS Workflow
1. **Best-of-N** generates `N` solutions for `q`, applying **PRM** to rank steps:
- **Selected Steps** (blue) are retained; **Rejected Steps** (orange) are discarded.
2. **Beam Search** narrows the search space by retaining top-N steps per decision.
3. **MCTS** iteratively:
- **Selects** nodes with highest UCT scores.
- **Expands** the tree by adding child nodes.
- **Simulates** node values via rollouts.
- **Backpropagates** rewards to update node values.
---
### Key Observations
1. **Hybrid Architecture**: RL Base TTS focuses on policy optimization, while Search Base TTS emphasizes efficient exploration via PRM and MCTS.
2. **Reward Integration**: The AIRL Discriminator bridges RL and search by providing step-wise feedback, enabling policy updates that align with search-based exploration.
3. **PRM Role**: Acts as a filter in Beam Search, ensuring computational efficiency by discarding low-quality steps.
4. **MCTS Dynamics**: Combines selection (greedy), expansion (breadth), and simulation (depth) to balance exploration and exploitation.
---
### Interpretation
- **Reinforcement Learning Component**: The AIRL Discriminator and policy updates suggest a focus on learning reward-shaping functions to guide search, improving sample efficiency.
- **Search-Based Component**: Best-of-N and Beam Search prioritize breadth-first exploration, while MCTS adds depth via simulation, enabling scalable decision-making.
- **PRM as a Bridge**: By ranking steps, PRM reduces the search space, making Beam Search feasible in complex environments.
- **Uncertainty in Reward Design**: The use of both step-wise (J_AIRL) and outcome (J_GRPO) rewards implies a trade-off between short-term and long-term objectives, requiring careful tuning.
This architecture demonstrates a principled integration of RL and search, leveraging policy learning for reward guidance and search methods for efficient solution discovery.