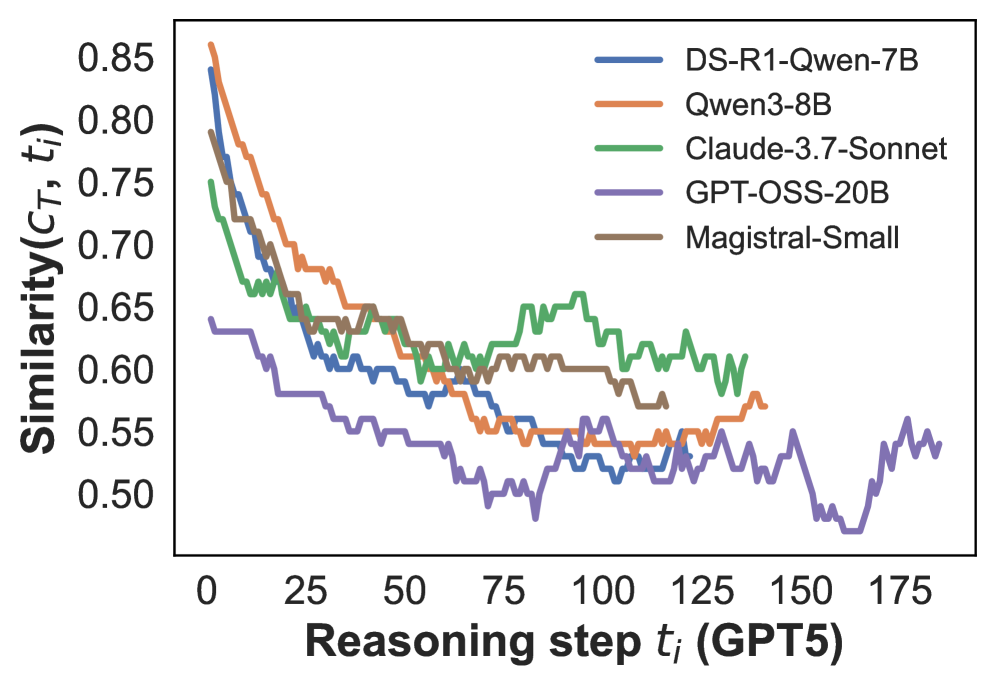
## Line Graph: Similarity Decay Across Reasoning Steps (GPT5)
### Overview
The image depicts a line graph comparing the similarity decay of five AI models over reasoning steps (t_i) measured in GPT5 units. The y-axis represents similarity scores (C_T, t_i) ranging from 0.50 to 0.85, while the x-axis spans 0 to 175 reasoning steps. Five distinct data series are plotted, each corresponding to a different model.
### Components/Axes
- **X-axis**: "Reasoning step t_i (GPT5)" (0–175, linear scale)
- **Y-axis**: "Similarity (C_T, t_i)" (0.50–0.85, linear scale)
- **Legend**:
- Blue: DS-R1-Qwen-7B
- Orange: Qwen3-8B
- Green: Claude-3.7-Sonnet
- Purple: GPT-OSS-20B
- Brown: Magistral-Small
- **Data Series**: Five colored lines with jagged trends, indicating stepwise measurements.
### Detailed Analysis
1. **DS-R1-Qwen-7B (Blue)**:
- Starts at ~0.85 similarity at t_i=0.
- Declines sharply to ~0.60 by t_i=50.
- Stabilizes with minor fluctuations between t_i=75–175.
2. **Qwen3-8B (Orange)**:
- Begins at ~0.80 similarity at t_i=0.
- Gradual decline to ~0.55 by t_i=100.
- Slight recovery to ~0.58 by t_i=150.
3. **Claude-3.7-Sonnet (Green)**:
- Initial similarity ~0.75 at t_i=0.
- Sharp drop to ~0.60 by t_i=50.
- Fluctuates between ~0.55–0.65 until t_i=175.
4. **GPT-OSS-20B (Purple)**:
- Lowest starting point (~0.60 at t_i=0).
- Steep decline to ~0.50 by t_i=50.
- Erratic fluctuations between ~0.45–0.55 until t_i=175.
5. **Magistral-Small (Brown)**:
- Mid-range start (~0.70 at t_i=0).
- Gradual decline to ~0.58 by t_i=100.
- Stabilizes with minor oscillations until t_i=175.
### Key Observations
- **Initial Decline**: All models show rapid similarity decay in the first 50 steps.
- **Stability Variance**: DS-R1-Qwen-7B and Magistral-Small stabilize faster than others.
- **Lowest Performance**: GPT-OSS-20B consistently exhibits the lowest similarity.
- **Notable Dip**: Claude-3.7-Sonnet shows a pronounced drop at t_i=50, followed by volatility.
### Interpretation
The graph illustrates how similarity to a target metric (C_T) degrades as reasoning steps increase. Models with higher initial similarity (DS-R1-Qwen-7B, Qwen3-8B) degrade more rapidly, suggesting potential overfitting or inefficiency in maintaining coherence over extended reasoning. The persistent low performance of GPT-OSS-20B may indicate architectural limitations or training data gaps. The green line’s volatility (Claude-3.7-Sonnet) could reflect sensitivity to specific reasoning tasks. Notably, no model maintains high similarity beyond ~100 steps, highlighting a universal challenge in long-context reasoning for current AI systems.