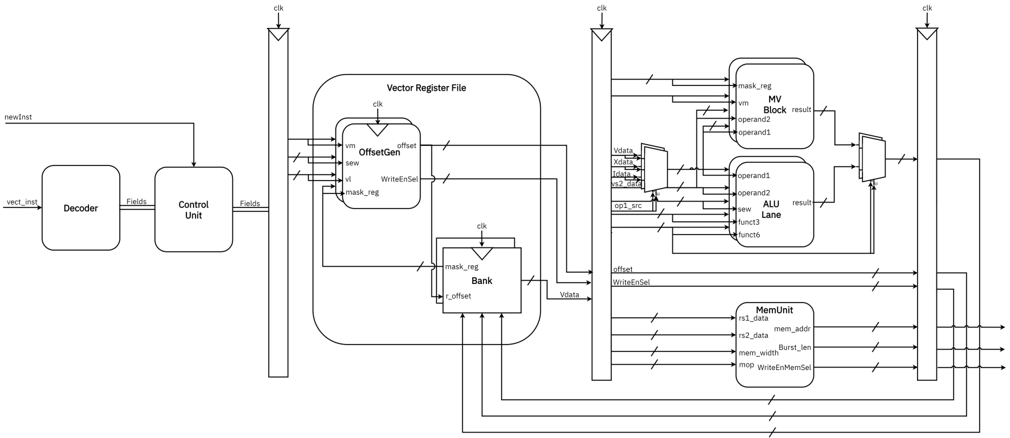
## System Architecture Diagram: Vector Processing Unit
### Overview
The diagram illustrates a complex vector processing unit architecture with multiple interconnected components. It shows data flow paths between functional blocks including a Decoder, Control Unit, Vector Register File, MV Block, ALU Lane, and MemUnit. The system appears designed for parallel vector operations with memory management capabilities.
### Components/Axes
**Key Components:**
1. **Decoder** (leftmost block)
- Input: `newInst`
- Outputs: `Fields`, `vec_inst`
2. **Control Unit** (adjacent to Decoder)
- Inputs: `Fields`
- Outputs: `mask_reg`, `r_offset`
3. **Vector Register File** (central block)
- Inputs: `vec_inst`, `mask_reg`, `r_offset`
- Outputs: `vm`, `offset`, `vm`, `operand1`, `operand2`
4. **MV Block** (right section)
- Inputs: `vm`, `operand1`, `operand2`
- Outputs: `result`
5. **ALU Lane** (right section)
- Inputs: `operand1`, `operand2`, `func3`, `func6`
- Outputs: `result`
6. **MemUnit** (bottom section)
- Inputs: `rs1_data`, `rs2_data`, `mem_addir`, `mem_width`, `mop`
- Outputs: `WriteEnMemSel`
**Data Flow Paths:**
- `newInst` → Decoder → Control Unit
- Decoder → Vector Register File (via `vec_inst`)
- Control Unit → Vector Register File (via `mask_reg`, `r_offset`)
- Vector Register File → MV Block (via `vm`, `operand1`, `operand2`)
- Vector Register File → ALU Lane (via `operand1`, `operand2`, `func3`, `func6`)
- ALU Lane → MV Block (via `result`)
- MemUnit interacts with ALU Lane via `rs1_data`, `rs2_data`, `mem_addir`
### Detailed Analysis
**Component Connections:**
1. **Decoder** receives `newInst` and splits output into:
- `Fields` (to Control Unit)
- `vec_inst` (to Vector Register File)
2. **Control Unit** processes `Fields` to generate:
- `mask_reg` (to Vector Register File)
- `r_offset` (to Vector Register File)
3. **Vector Register File** manages:
- Vector data (`vm`)
- Memory offsets (`offset`)
- Operand registers (`operand1`, `operand2`)
4. **MV Block** performs:
- Vector operations using `vm`, `operand1`, `operand2`
- Produces `result`
5. **ALU Lane** handles:
- Arithmetic/logic operations (`func3`, `func6`)
- Produces `result` for MV Block
6. **MemUnit** manages:
- Register data (`rs1_data`, `rs2_data`)
- Memory addressing (`mem_addir`)
- Write enable (`WriteEnMemSel`)
### Key Observations
1. **Parallel Processing Paths:** Multiple data paths suggest concurrent operations between MV Block and ALU Lane
2. **Memory Integration:** MemUnit connects to both ALU Lane and Vector Register File, indicating tight memory-ALU integration
3. **Control Flow:** Control Unit acts as central coordinator between Decoder and Vector Register File
4. **Vector Specialization:** Presence of dedicated MV Block indicates vector-specific optimizations
### Interpretation
This architecture demonstrates a sophisticated vector processing design optimized for:
1. **High-throughput vector operations** through parallel ALU and MV processing
2. **Efficient memory access** via integrated MemUnit with ALU Lane
3. **Fine-grained control** through dedicated Control Unit managing register operations
4. **Specialized vector handling** via dedicated MV Block and Vector Register File
The system appears designed for applications requiring intensive vector computations (e.g., scientific computing, graphics processing) with low-latency memory access. The tight coupling between ALU operations and memory management suggests optimized performance for data-intensive workloads.