\n
## Scatter Plot: Model Performance Comparison
### Overview
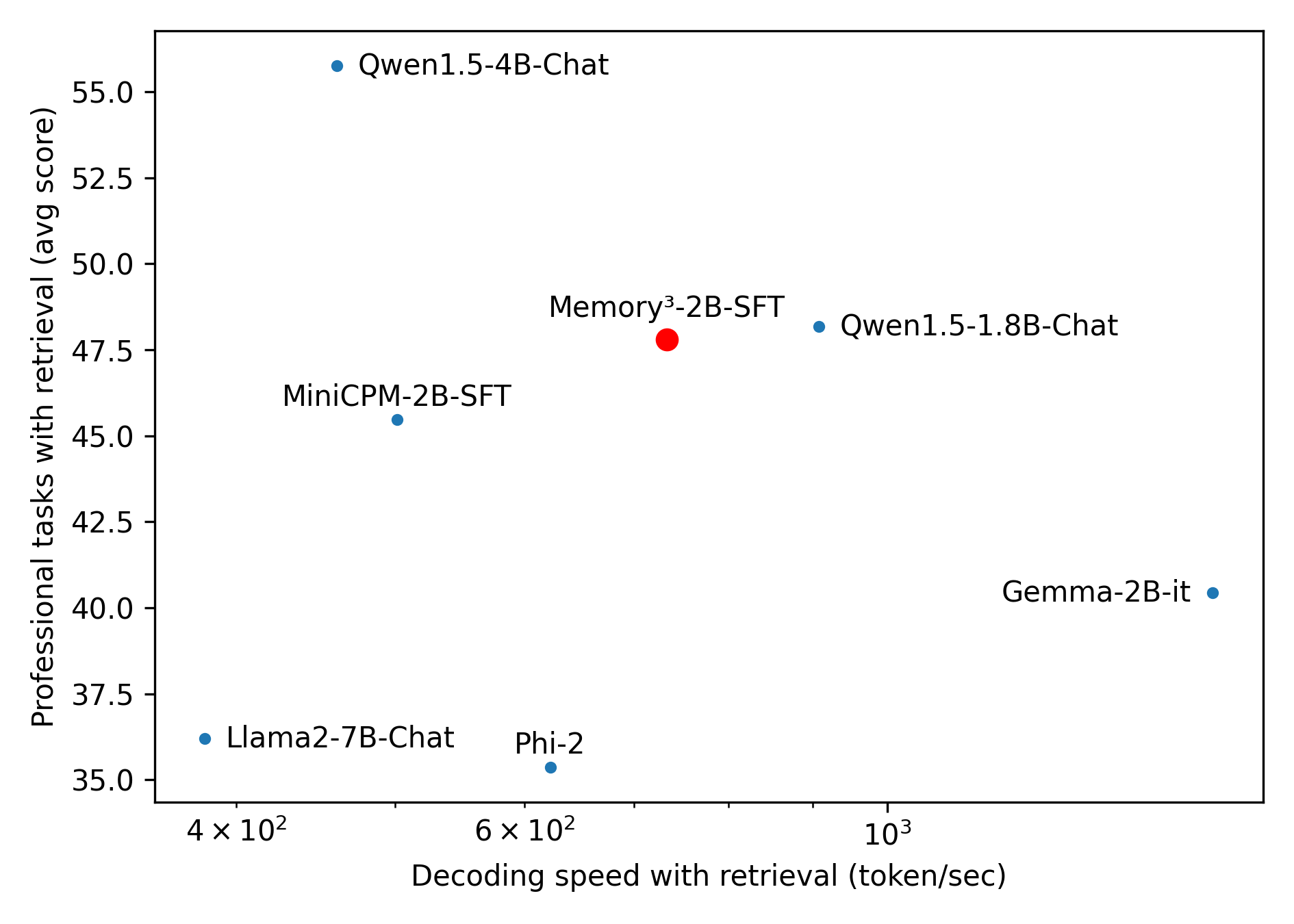
This image presents a scatter plot comparing the performance of several language models on professional tasks with retrieval, plotted against their decoding speed with retrieval. The plot displays six models: Qwen1.5-4B-Chat, Qwen1.5-1.8B-Chat, Memory³-2B-SFT, MiniCPM-2B-SFT, Gemma-2B-it, and Llama2-7B-Chat, along with Phi-2.
### Components/Axes
* **X-axis:** Decoding speed with retrieval (token/sec). Scale is logarithmic, ranging from approximately 4 x 10² to 10³.
* **Y-axis:** Professional tasks with retrieval (avg score), ranging from approximately 35.0 to 55.0.
* **Data Points:** Each point represents a language model.
* **Model Labels:** Each data point is labeled with the model name.
### Detailed Analysis
The data points are as follows (approximate values read from the plot):
* **Qwen1.5-4B-Chat:** Decoding speed ≈ 5.5 x 10² token/sec, Professional tasks score ≈ 54.5.
* **Qwen1.5-1.8B-Chat:** Decoding speed ≈ 8 x 10² token/sec, Professional tasks score ≈ 48.0.
* **Memory³-2B-SFT:** Decoding speed ≈ 6.5 x 10² token/sec, Professional tasks score ≈ 47.0.
* **MiniCPM-2B-SFT:** Decoding speed ≈ 5 x 10² token/sec, Professional tasks score ≈ 45.5.
* **Gemma-2B-it:** Decoding speed ≈ 10³ token/sec, Professional tasks score ≈ 40.5.
* **Llama2-7B-Chat:** Decoding speed ≈ 4 x 10² token/sec, Professional tasks score ≈ 36.5.
* **Phi-2:** Decoding speed ≈ 6 x 10² token/sec, Professional tasks score ≈ 35.0.
**Trends:**
* Generally, there's a positive correlation between decoding speed and professional tasks score, though it's not a strong linear relationship.
* Qwen1.5-4B-Chat exhibits the highest professional tasks score and a moderate decoding speed.
* Llama2-7B-Chat has the lowest professional tasks score and the slowest decoding speed.
* Gemma-2B-it has the fastest decoding speed but a relatively lower professional tasks score.
### Key Observations
* Qwen1.5-4B-Chat appears to be the best-performing model in terms of professional tasks score.
* Phi-2 has the lowest score, and Llama2-7B-Chat is close behind.
* There's a cluster of models (Memory³-2B-SFT, MiniCPM-2B-SFT, Qwen1.5-1.8B-Chat) with similar performance levels.
* Gemma-2B-it prioritizes decoding speed over professional tasks score.
### Interpretation
The scatter plot illustrates the trade-off between decoding speed and performance on professional tasks for different language models. Models like Qwen1.5-4B-Chat achieve high scores on professional tasks but at the cost of slower decoding speeds. Conversely, Gemma-2B-it offers fast decoding but with a lower performance score. This suggests that the optimal model choice depends on the specific application requirements. If high accuracy on professional tasks is paramount, Qwen1.5-4B-Chat might be preferred. If speed is critical, Gemma-2B-it could be a better option. The logarithmic scale on the x-axis indicates that the impact of decoding speed diminishes as it increases, suggesting that there may be a point of diminishing returns. The relatively wide spread of data points indicates that model architecture and training data play a significant role in determining both decoding speed and performance. The positioning of Phi-2 and Llama2-7B-Chat at the bottom-left suggests they may be less suitable for applications requiring both speed and accuracy.