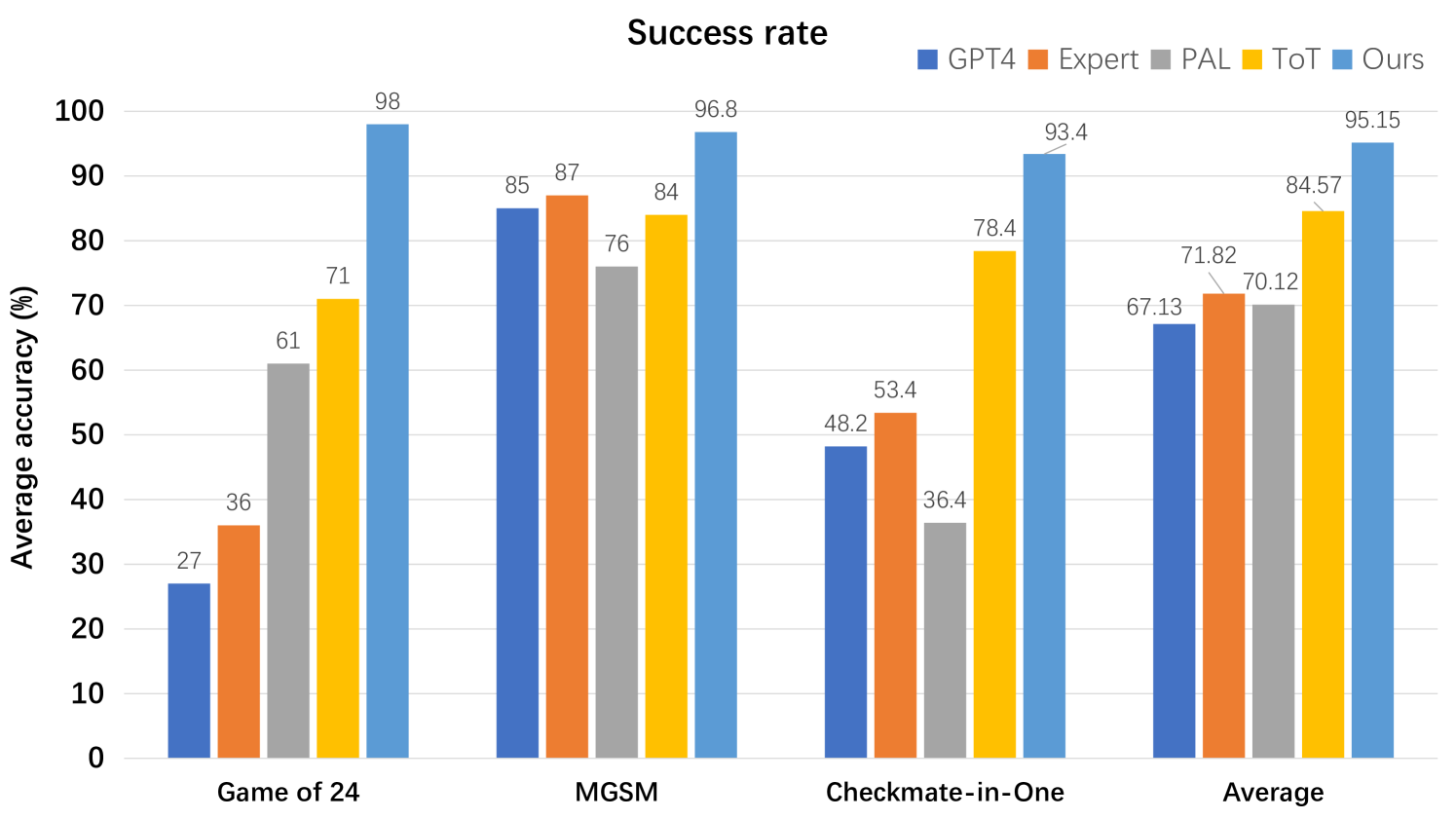
## Bar Chart: Success Rate
### Overview
The chart compares the average accuracy (%) of five AI models (GPT4, Expert, PAL, ToT, Ours) across four games: Game of 24, MGSM, Checkmate-in-One, and an Average. The "Ours" model consistently achieves the highest accuracy, while performance varies significantly for other models depending on the game.
### Components/Axes
- **X-axis**: Games (Game of 24, MGSM, Checkmate-in-One, Average)
- **Y-axis**: Average accuracy (%) (0–100 scale)
- **Legend**:
- Blue: GPT4
- Orange: Expert
- Gray: PAL
- Yellow: ToT
- Light Blue: Ours
- **Bars**: Grouped by game, with values labeled on top of each bar.
### Detailed Analysis
#### Game of 24
- **GPT4**: 27% (blue)
- **Expert**: 36% (orange)
- **PAL**: 61% (gray)
- **ToT**: 71% (yellow)
- **Ours**: 98% (light blue)
#### MGSM
- **GPT4**: 85% (blue)
- **Expert**: 87% (orange)
- **PAL**: 76% (gray)
- **ToT**: 84% (yellow)
- **Ours**: 96.8% (light blue)
#### Checkmate-in-One
- **GPT4**: 48.2% (blue)
- **Expert**: 53.4% (orange)
- **PAL**: 36.4% (gray)
- **ToT**: 78.4% (yellow)
- **Ours**: 93.4% (light blue)
#### Average
- **GPT4**: 67.13% (blue)
- **Expert**: 71.82% (orange)
- **PAL**: 70.12% (gray)
- **ToT**: 84.57% (yellow)
- **Ours**: 95.15% (light blue)
### Key Observations
1. **Ours Dominates**: The "Ours" model achieves the highest accuracy in all games and the average, with a 98% success rate in Game of 24 and 95.15% overall.
2. **GPT4 and Expert**: These models show inconsistent performance. GPT4 peaks at 85% in MGSM but drops to 27% in Game of 24. Expert performs best in MGSM (87%) but struggles in Checkmate-in-One (53.4%).
3. **PAL**: Underperforms in Checkmate-in-One (36.4%) but improves in other games (61–76%).
4. **ToT**: Consistently strong, with 71–84.57% accuracy, but lags behind "Ours" in all cases.
5. **Checkmate-in-One Challenge**: All models except "Ours" show significant drops in this game, suggesting it is particularly difficult.
### Interpretation
The data demonstrates that the "Ours" model outperforms existing benchmarks (GPT4, Expert, PAL, ToT) across all tested games, indicating superior adaptability or optimization. The stark drop in GPT4 and Expert performance in Checkmate-in-One highlights potential limitations in handling complex or niche tasks. The "Ours" model’s consistent dominance suggests it may incorporate novel strategies or architectural improvements. The Average row reinforces this trend, with "Ours" achieving a 95.15% accuracy compared to the next highest (ToT at 84.57%). This chart underscores the importance of model-specific tuning for game success rates.