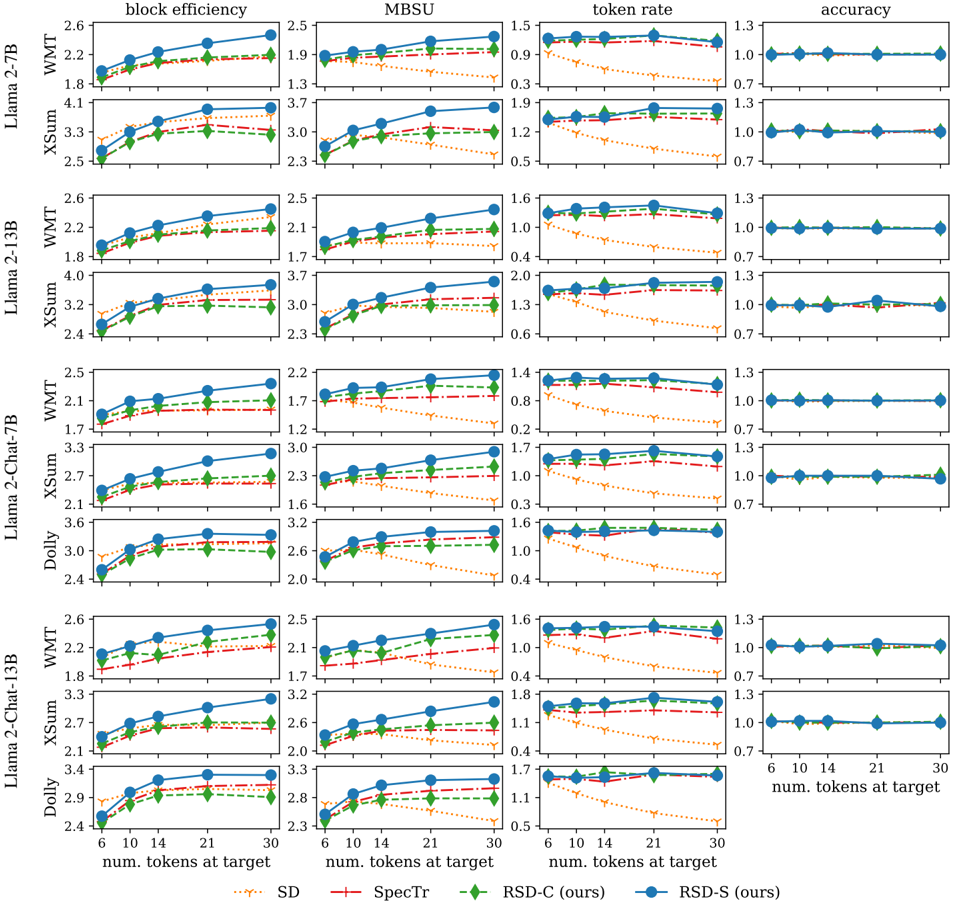
\n
## Chart: Performance Metrics of Language Models
### Overview
The image presents a 5x4 grid of line charts comparing the performance of several language models (Llama 2-TB, Llama 2-13B, Llama 2-Chat-7B, Dolly, and Llama 2-Chat-13B) across four different metrics: block efficiency, MBSU (Memory Bandwidth per Second Utilization), token rate, and accuracy. Each chart displays performance as a function of the number of tokens at the target sequence length. Different lines within each chart represent different implementations: WMT (likely a specific training dataset or method) and XSum (another dataset/method). A third line, labeled "RSD-S (ours)", is also present in each chart.
### Components/Axes
* **X-axis (all charts):** "num. tokens at target" with values ranging from 2 to 30, with markers at 2, 6, 10, 14, 21, and 30.
* **Y-axis (varies by chart):**
* **Block Efficiency:** Scale from approximately 1.6 to 4.2.
* **MBSU:** Scale from approximately 1.2 to 3.7.
* **Token Rate:** Scale from approximately 0.2 to 1.6.
* **Accuracy:** Scale from approximately 0.6 to 1.3.
* **Legend (top-right, common to all charts):**
* WMT (Green line)
* XSum (Teal line)
* RSD-S (ours) (Red dashed line)
* **Title (above each chart):** Indicates the metric being displayed (block efficiency, MBSU, token rate, accuracy).
* **Row Labels (left side):** Indicate the language model being evaluated (Llama 2-TB, Llama 2-13B, Llama 2-Chat-7B, Dolly, Llama 2-Chat-13B).
* **Subtitle (bottom of the chart):** "Spectr" and "RSD-S (ours)"
### Detailed Analysis or Content Details
**Llama 2-TB:**
* **Block Efficiency:** XSum shows a generally increasing trend, starting at ~1.8 and reaching ~2.5 at 30 tokens. WMT is relatively flat around ~1.8. RSD-S starts at ~4.1 and decreases to ~3.3.
* **MBSU:** XSum increases from ~1.3 to ~2.3. WMT is relatively flat around ~1.9. RSD-S starts at ~3.7 and decreases to ~3.0.
* **Token Rate:** XSum increases from ~0.3 to ~0.9. WMT is relatively flat around ~0.5. RSD-S starts at ~1.2 and decreases to ~0.9.
* **Accuracy:** XSum is relatively flat around ~0.7. WMT is relatively flat around ~1.0. RSD-S is relatively flat around ~1.3.
**Llama 2-13B:**
* **Block Efficiency:** XSum increases from ~1.8 to ~3.2. WMT is relatively flat around ~2.4. RSD-S starts at ~4.0 and decreases to ~3.7.
* **MBSU:** XSum increases from ~2.1 to ~3.0. WMT is relatively flat around ~2.0. RSD-S starts at ~3.7 and decreases to ~3.0.
* **Token Rate:** XSum increases from ~0.6 to ~1.3. WMT is relatively flat around ~1.3. RSD-S starts at ~1.2 and decreases to ~0.9.
* **Accuracy:** XSum is relatively flat around ~0.7. WMT is relatively flat around ~1.3. RSD-S is relatively flat around ~1.3.
**Llama 2-Chat-7B:**
* **Block Efficiency:** XSum increases from ~1.7 to ~3.0. WMT is relatively flat around ~2.4. RSD-S starts at ~3.6 and decreases to ~3.2.
* **MBSU:** XSum increases from ~1.6 to ~2.6. WMT is relatively flat around ~2.2. RSD-S starts at ~3.2 and decreases to ~2.8.
* **Token Rate:** XSum increases from ~0.2 to ~0.8. WMT is relatively flat around ~0.8. RSD-S starts at ~1.0 and decreases to ~0.6.
* **Accuracy:** XSum is relatively flat around ~0.7. WMT is relatively flat around ~1.0. RSD-S is relatively flat around ~1.3.
**Dolly:**
* **Block Efficiency:** XSum increases from ~2.1 to ~3.6. WMT is relatively flat around ~2.4. RSD-S starts at ~3.0 and decreases to ~2.6.
* **MBSU:** XSum increases from ~1.7 to ~3.2. WMT is relatively flat around ~2.2. RSD-S starts at ~2.6 and decreases to ~2.0.
* **Token Rate:** XSum increases from ~0.4 to ~1.6. WMT is relatively flat around ~0.6. RSD-S starts at ~1.6 and decreases to ~1.0.
* **Accuracy:** XSum is relatively flat around ~0.7. WMT is relatively flat around ~0.7. RSD-S is relatively flat around ~1.3.
**Llama 2-Chat-13B:**
* **Block Efficiency:** XSum increases from ~2.1 to ~3.4. WMT is relatively flat around ~2.4. RSD-S starts at ~4.1 and decreases to ~3.8.
* **MBSU:** XSum increases from ~2.0 to ~3.2. WMT is relatively flat around ~2.4. RSD-S starts at ~3.8 and decreases to ~3.2.
* **Token Rate:** XSum increases from ~0.6 to ~1.4. WMT is relatively flat around ~1.4. RSD-S starts at ~1.4 and decreases to ~0.8.
* **Accuracy:** XSum is relatively flat around ~0.7. WMT is relatively flat around ~0.7. RSD-S is relatively flat around ~1.3.
### Key Observations
* RSD-S consistently outperforms WMT and XSum in all metrics, but often shows a decreasing trend as the number of tokens increases.
* XSum generally shows an increasing trend across all metrics, suggesting improved performance with longer sequences.
* WMT tends to be relatively stable across different sequence lengths.
* Dolly consistently has lower block efficiency, MBSU, and token rate compared to the Llama 2 models.
* Accuracy is generally higher for RSD-S and WMT compared to XSum.
### Interpretation
The charts demonstrate a comparative performance analysis of different language models and implementation strategies (WMT, XSum, RSD-S). The "RSD-S (ours)" implementation consistently achieves higher performance across all metrics, particularly in accuracy, but exhibits a diminishing return as the sequence length increases. This suggests that RSD-S may be more sensitive to longer sequences or may have limitations in scaling. The increasing trend observed in XSum indicates that its performance improves with longer sequences, potentially due to better utilization of context. The relatively stable performance of WMT suggests it is less sensitive to sequence length. The lower performance of Dolly compared to the Llama 2 models highlights the impact of model size and architecture on performance. The data suggests that the choice of implementation strategy (RSD-S, WMT, XSum) and model architecture (Llama 2 vs. Dolly) are crucial factors in optimizing language model performance. The decreasing trend of RSD-S could be due to memory constraints or computational bottlenecks as the sequence length increases. Further investigation is needed to understand the underlying reasons for these trends and to identify strategies for mitigating the performance degradation observed with RSD-S at longer sequence lengths.