\n
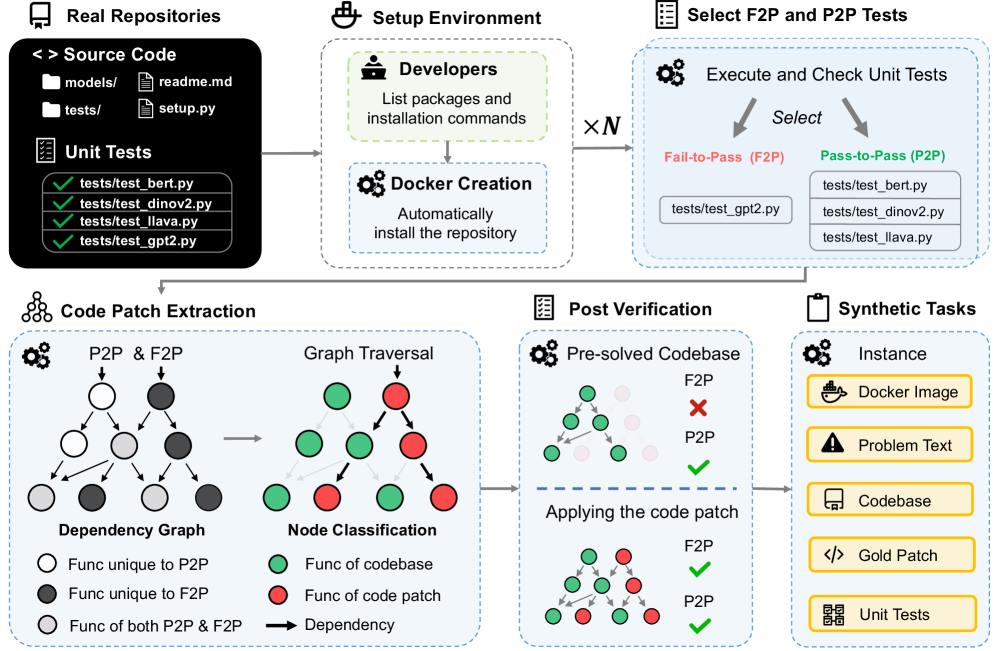
## Diagram: Automated Patch Verification Pipeline
### Overview
This diagram illustrates an automated pipeline for verifying code patches, specifically focusing on identifying Fail-to-Pass (F2P) and Pass-to-Pass (P2P) tests. The pipeline begins with real repositories, proceeds through environment setup, test selection and execution, code patch extraction, post-verification, and culminates in synthetic tasks. The diagram uses icons and flow arrows to represent the process.
### Components/Axes
The diagram is segmented into several key areas:
* **Real Repositories:** Contains a folder icon labeled "Source Code" with subfolders "models/" and "tests/". Files listed within "tests/" are "test\_bert.py", "test\_dinov2.py", "test\_llava.py", and "test\_gpt2.py".
* **Setup Environment:** Includes icons for "Developers" (listing packages and installation commands) and "Docker Creation" (automatically installing the repository). An arrow labeled "X N" connects these two components.
* **Select F2P and P2P Tests:** Shows a selection process leading to two categories: "Fail-to-Pass (F2P)" and "Pass-to-Pass (P2P)". Example tests listed under each are "tests/test\_gpt2.py".
* **Execute and Check Unit Tests:** An arrow labeled "Select" points from the previous step to this one.
* **Code Patch Extraction:** Depicts "P2P & F2P" leading to a "Dependency Graph" and "Node Classification".
* **Post Verification:** Shows "Pre-solved Codebase" with F2P and P2P states (one marked with an 'X' and one with a checkmark) and "Applying the code patch" with similar F2P and P2P states.
* **Synthetic Tasks:** Includes icons for "Instance", "Docker Image", "Problem Text", "Database", "Gold Patch", and "Unit Tests".
Legends are provided for:
* **Dependency Graph:**
* White circle: "Func unique to P2P"
* Black circle: "Func unique to F2P"
* Gray circle: "Func of both P2P & F2P"
* **Node Classification:**
* Green circle: "Func of codebase"
* Red circle: "Func of code patch"
* Arrow: "Dependency"
### Detailed Analysis or Content Details
The pipeline flow is as follows:
1. **Real Repositories:** The process starts with source code and unit tests. The listed tests are: `test_bert.py`, `test_dinov2.py`, `test_llava.py`, and `test_gpt2.py`.
2. **Setup Environment:** Developers define packages and installation commands, which are then used by Docker Creation to automatically install the repository. The "X N" arrow suggests a scaling or iterative process.
3. **Select F2P and P2P Tests:** Tests are categorized as either Fail-to-Pass (F2P) or Pass-to-Pass (P2P). `tests/test_gpt2.py` is explicitly listed as an example.
4. **Execute and Check Unit Tests:** Selected tests are executed.
5. **Code Patch Extraction:** Patches are extracted for both P2P and F2P tests. This leads to the creation of a Dependency Graph and Node Classification.
* **Dependency Graph:** Visualizes the relationships between functions, categorized by whether they are unique to P2P, F2P, or present in both.
* **Node Classification:** Classifies nodes based on whether they belong to the codebase or the code patch, indicating dependencies.
6. **Post Verification:** The code patch is applied to a pre-solved codebase. The outcome is verified for both F2P and P2P scenarios. One F2P instance is marked with an 'X' (failure), while one P2P instance is marked with a checkmark (success).
7. **Synthetic Tasks:** The final stage involves creating an instance, Docker image, identifying problem text, utilizing a database, comparing against a gold patch, and running unit tests.
### Key Observations
* The pipeline explicitly distinguishes between Fail-to-Pass (F2P) and Pass-to-Pass (P2P) tests, suggesting a focus on identifying regressions and verifying fixes.
* The Dependency Graph and Node Classification steps provide insights into the impact of code changes.
* The Post Verification stage includes a visual indicator of success or failure for both F2P and P2P scenarios.
* The use of Docker suggests a containerized environment for reproducibility.
* The "X N" arrow implies a potentially iterative or scaled process in the Setup Environment.
### Interpretation
This diagram represents a sophisticated automated system for verifying code patches. The pipeline aims to ensure that changes do not introduce regressions (F2P) and that fixes are correctly applied (P2P). The use of dependency graphs and node classification allows for a detailed analysis of the impact of code changes. The synthetic tasks at the end suggest a comprehensive testing strategy. The pipeline is designed to be automated and reproducible, leveraging Docker for environment consistency. The diagram highlights the importance of rigorous testing in software development, particularly in identifying and preventing regressions. The visual representation of success/failure in the Post Verification stage provides a clear and concise overview of the patch verification process. The diagram doesn't provide quantitative data, but rather a conceptual overview of the workflow. It suggests a system designed for continuous integration and automated testing.