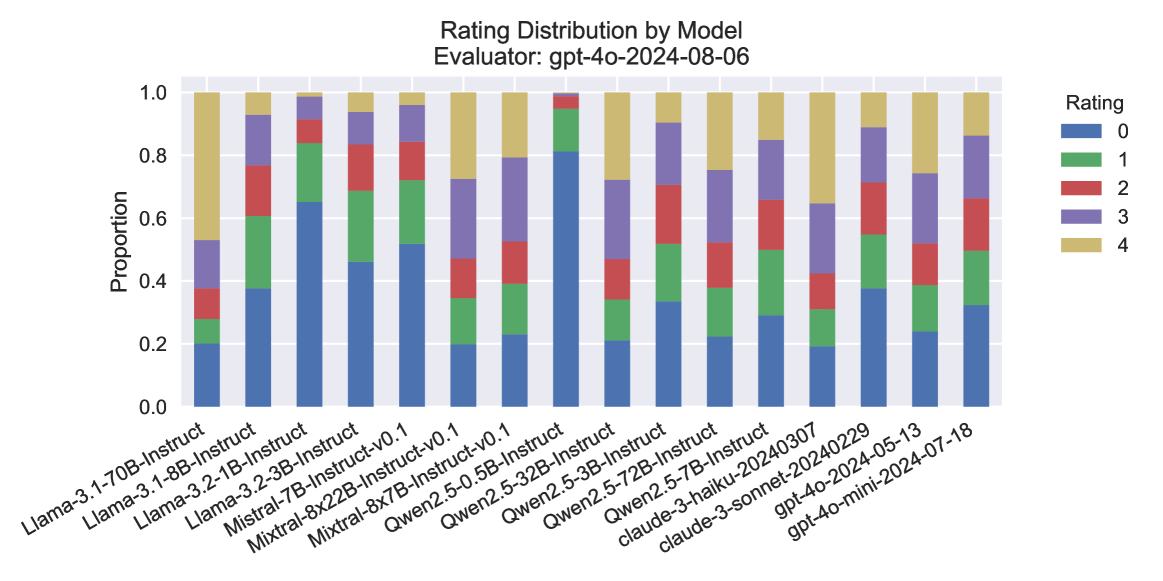
## Bar Chart: Rating Distribution by Model
### Overview
The chart displays the distribution of ratings (0–4) for various AI models evaluated by the "gpt-4o-2024-08-06" evaluator. Each bar represents a model, with segments colored according to the proportion of each rating. The y-axis shows the proportion of ratings (0.0–1.0), while the x-axis lists model names and versions.
### Components/Axes
- **Title**: "Rating Distribution by Model"
- **X-axis**: Model names and versions (e.g., "Llama-3-1-70B-Instruct", "Mistral-7B-Instruct-v0.1", "Claude-3-haiku-20240307").
- **Y-axis**: "Proportion" (0.0–1.0), with ticks at 0.0, 0.2, 0.4, 0.6, 0.8, 1.0.
- **Legend**:
- **Blue**: Rating 0
- **Green**: Rating 1
- **Red**: Rating 2
- **Purple**: Rating 3
- **Yellow**: Rating 4
### Detailed Analysis
- **Model Ratings**:
- **Llama-3-1-70B-Instruct**: High proportion of yellow (rating 4) and purple (rating 3), with smaller segments for lower ratings.
- **Llama-3-1-8B-Instruct**: Balanced distribution, with notable green (rating 1) and red (rating 2) segments.
- **Mistral-7B-Instruct-v0.1**: Dominant yellow (rating 4) and purple (rating 3), with minimal blue (rating 0).
- **Claude-3-haiku-20240307**: High yellow (rating 4) and purple (rating 3), with a smaller red (rating 2) segment.
- **gpt-4o-mini-2024-07-18**: Moderate yellow (rating 4) and purple (rating 3), with a significant red (rating 2) segment.
- **Proportions**:
- Most models show a strong presence of higher ratings (3–4), with yellow (rating 4) being the largest segment for many.
- Lower ratings (0–2) are less common, though some models (e.g., Llama-3-1-8B-Instruct) have notable red (rating 2) segments.
### Key Observations
- **High-Performing Models**: Models like "Mistral-7B-Instruct-v0.1" and "Claude-3-haiku-20240307" exhibit a high proportion of top ratings (4), suggesting strong performance.
- **Moderate Performers**: "Llama-3-1-8B-Instruct" and "gpt-4o-mini-2024-07-18" show a mix of mid-range ratings (2–3), indicating variability in performance.
- **Outliers**: "Llama-3-1-70B-Instruct" has the highest proportion of rating 4, while "Llama-3-1-8B-Instruct" has a relatively high proportion of rating 2.
### Interpretation
The chart highlights that most models evaluated by "gpt-4o-2024-08-06" received predominantly high ratings (3–4), with yellow (rating 4) being the most common. This suggests that the evaluator generally found the models to be of high quality. However, variations exist:
- **Model Size vs. Performance**: Larger models (e.g., Llama-3-1-70B-Instruct) may perform better, as indicated by their higher rating 4 proportions.
- **Version Differences**: Newer versions (e.g., Mistral-7B-Instruct-v0.1) often show improved ratings compared to older ones.
- **Rating Distribution**: The presence of red (rating 2) segments in some models (e.g., Llama-3-1-8B-Instruct) indicates that while some models are strong, others have notable weaknesses.
The data underscores the importance of model architecture and versioning in performance, with higher-rated models likely being more reliable or accurate for specific tasks. The evaluator's consistent use of high ratings (4) across models suggests a generally positive assessment, but the distribution of lower ratings (0–2) highlights areas for improvement.