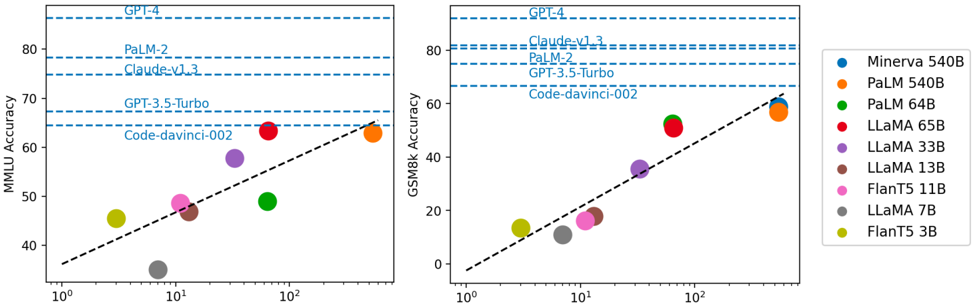
## Scatter Plot Comparison: Model Accuracy on MMLU and GSM8k
### Overview
The image presents two scatter plots comparing the accuracy of various language models on two different benchmarks: MMLU (Massive Multitask Language Understanding) and GSM8k (Grade School Math 8K). The x-axis represents model size, displayed on a logarithmic scale, while the y-axis represents accuracy. Each plot shows the performance of several models, with a dashed line indicating a general trend. The legend on the right identifies each model by color.
### Components/Axes
**Left Plot (MMLU Accuracy):**
* **Title:** MMLU Accuracy
* **Y-axis:** MMLU Accuracy, with a linear scale from 40 to 80 in increments of 10.
* **X-axis:** Model Size (in billions of parameters, implied), with a logarithmic scale from 10^0 (1) to 10^2 (100).
* **Horizontal Dashed Lines (Top to Bottom):**
* GPT-4 (Accuracy ~85)
* PaLM-2 (Accuracy ~78)
* Claude-v1.3 (Accuracy ~75)
* GPT-3.5-Turbo (Accuracy ~68)
* Code-davinci-002 (Accuracy ~64)
**Right Plot (GSM8k Accuracy):**
* **Title:** GSM8k Accuracy
* **Y-axis:** GSM8k Accuracy, with a linear scale from 0 to 80 in increments of 20.
* **X-axis:** Model Size (in billions of parameters, implied), with a logarithmic scale from 10^0 (1) to 10^2 (100).
* **Horizontal Dashed Lines (Top to Bottom):**
* GPT-4 (Accuracy ~82)
* PaLM-2 (Accuracy ~77)
* Claude-v1.3 (Accuracy ~74)
* GPT-3.5-Turbo (Accuracy ~67)
* Code-davinci-002 (Accuracy ~62)
**Legend (Right Side):**
* Blue: Minerva 540B
* Orange: PaLM 540B
* Green: PaLM 64B
* Red: LLaMA 65B
* Purple: LLaMA 33B
* Brown: LLaMA 13B
* Pink: FlanT5 11B
* Gray: LLaMA 7B
* Olive/Yellow: FlanT5 3B
### Detailed Analysis
**Left Plot (MMLU Accuracy):**
* **FlanT5 3B (Olive/Yellow):** Located at approximately (2, 45).
* **LLaMA 7B (Gray):** Located at approximately (4, 35).
* **FlanT5 11B (Pink):** Located at approximately (8, 48).
* **LLaMA 13B (Brown):** Located at approximately (10, 47).
* **LLaMA 33B (Purple):** Located at approximately (18, 58).
* **PaLM 64B (Green):** Located at approximately (30, 50).
* **LLaMA 65B (Red):** Located at approximately (100, 64).
* **Trend:** The dashed line suggests a positive correlation between model size and MMLU accuracy.
**Right Plot (GSM8k Accuracy):**
* **FlanT5 3B (Olive/Yellow):** Located at approximately (2, 10).
* **LLaMA 7B (Gray):** Located at approximately (4, 15).
* **FlanT5 11B (Pink):** Located at approximately (8, 18).
* **LLaMA 13B (Brown):** Located at approximately (10, 20).
* **LLaMA 33B (Purple):** Located at approximately (18, 35).
* **PaLM 64B (Green):** Located at approximately (30, 30).
* **LLaMA 65B (Red):** Located at approximately (100, 55).
* **PaLM 540B (Orange):** Located at approximately (200, 60).
* **Trend:** The dashed line suggests a positive correlation between model size and GSM8k accuracy.
### Key Observations
* The horizontal dashed lines representing GPT-4, PaLM-2, Claude-v1.3, GPT-3.5-Turbo, and Code-davinci-002 serve as benchmarks for comparison.
* The Minerva 540B data point is missing from both plots.
* The performance of models on GSM8k is generally lower than on MMLU.
* There is a clear trend of increasing accuracy with increasing model size on both benchmarks.
### Interpretation
The scatter plots illustrate the relationship between model size and performance on two different types of tasks: general language understanding (MMLU) and mathematical reasoning (GSM8k). The data suggests that larger models tend to perform better on both benchmarks, although the improvement is not always linear. The horizontal lines provide a reference point, showing the performance of established models like GPT-4. The lower accuracy on GSM8k compared to MMLU indicates that mathematical reasoning is a more challenging task for these models. The absence of the Minerva 540B data point is an anomaly that could be due to missing data or a deliberate omission. The plots highlight the ongoing progress in language model development, with larger models achieving higher accuracy on complex tasks.