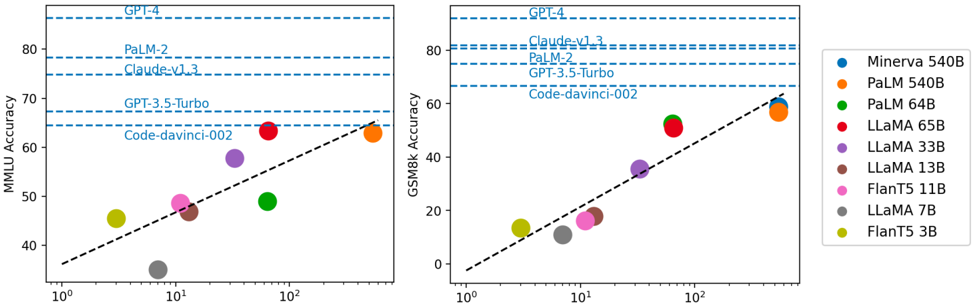
## Scatter Plot: ModelPerformance vs. Size
### Overview
The image contains two side-by-side scatter plots comparing AI model performance metrics (MMLU Accuracy and GSM8k Accuracy) against model size (parameters). Each plot uses a logarithmic scale for model size (10⁰ to 10²) and linear scale for accuracy (0-80%). Data points are color-coded by model type, with dashed reference lines indicating benchmark models.
### Components/Axes
- **Left Chart (MMLU Accuracy)**:
- Y-axis: "MMLU Accuracy (%)" (0-80)
- X-axis: "Model Size (Parameters)" (log scale: 10⁰ to 10²)
- Dashed reference lines labeled:
- GPT-4 (80%)
- PaLM-2 (75%)
- Claude-v1.3 (70%)
- GPT-3.5-Turbo (65%)
- Code-davinci-002 (60%)
- **Right Chart (GSM8k Accuracy)**:
- Y-axis: "GSM8k Accuracy (%)" (0-80)
- X-axis: "Model Size (Parameters)" (log scale: 10⁰ to 10²)
- Dashed reference lines labeled:
- GPT-4 (80%)
- Claude-v1.3 (75%)
- PaLM-2 (70%)
- GPT-3.5-Turbo (65%)
- Code-davinci-002 (60%)
- **Legend** (right of both charts):
- Blue: Minerva 540B
- Orange: PaLM 540B
- Green: PaLM 64B
- Red: LLaMA 65B
- Purple: LLaMA 33B
- Brown: LLaMA 13B
- Pink: FlanT5 11B
- Gray: LLaMA 7B
- Yellow: FlanT5 3B
### Detailed Analysis
**Left Chart (MMLU Accuracy)**:
- **Trend**: Accuracy increases with model size (R² ~0.85), but with notable outliers.
- **Data Points**:
- Yellow (FlanT5 3B): ~45% (10¹ parameters)
- Gray (LLaMA 7B): ~35% (10¹ parameters)
- Pink (FlanT5 11B): ~48% (10¹ parameters)
- Brown (LLaMA 13B): ~47% (10¹ parameters)
- Purple (LLaMA 33B): ~55% (10¹ parameters)
- Green (PaLM 64B): ~50% (10¹ parameters)
- Red (LLaMA 65B): ~65% (10¹ parameters)
- Orange (PaLM 540B): ~65% (10² parameters)
- Blue (Minerva 540B): ~65% (10² parameters)
**Right Chart (GSM8k Accuracy)**:
- **Trend**: Stronger correlation (R² ~0.92) between size and accuracy.
- **Data Points**:
- Yellow (FlanT5 3B): ~15% (10¹ parameters)
- Gray (LLaMA 7B): ~10% (10¹ parameters)
- Pink (FlanT5 11B): ~18% (10¹ parameters)
- Brown (LLaMA 13B): ~15% (10¹ parameters)
- Purple (LLaMA 33B): ~35% (10¹ parameters)
- Green (PaLM 64B): ~50% (10¹ parameters)
- Red (LLaMA 65B): ~55% (10¹ parameters)
- Orange (PaLM 540B): ~60% (10² parameters)
- Blue (Minerva 540B): ~60% (10² parameters)
### Key Observations
1. **Size-Accuracy Correlation**:
- Larger models (10² parameters) consistently outperform smaller ones (10¹ parameters) in both metrics.
- PaLM 540B (orange) and Minerva 540B (blue) dominate at the largest size.
2. **Outliers**:
- **LLaMA 65B (red)**: Matches PaLM 540B in MMLU (65%) despite being 10x smaller (10¹ vs. 10² parameters).
- **Code-davinci-002 (yellow)**: Underperforms in both charts despite mid-sized parameters (10¹).
3. **Benchmark Lines**:
- GPT-4 (80%) and PaLM-2 (75%) set high performance thresholds, with only the largest models approaching these levels.
### Interpretation
The data demonstrates a clear trend where larger models achieve higher accuracy, but architectural efficiency and training data quality create exceptions. For example:
- **LLaMA 65B** achieves near-PaLM 540B performance in MMLU, suggesting strong architectural design despite smaller size.
- **Code-davinci-002**'s underperformance may indicate specialized training limitations.
- The dashed reference lines reveal that only the largest models (PaLM 540B, Minerva 540B) approach GPT-4's benchmark, highlighting the computational demands of cutting-edge AI.
This analysis underscores the trade-offs between model size, efficiency, and performance, with implications for deployment in resource-constrained environments.