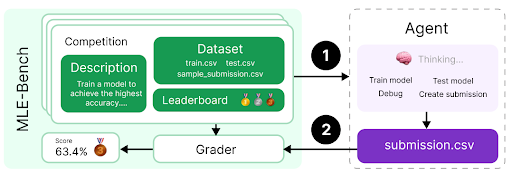
## Diagram: MLE-Bench Competition Workflow
### Overview
The image is a flowchart or process diagram illustrating the workflow of a machine learning competition benchmark called "MLE-Bench." It depicts the interaction between a competition environment (left) and an autonomous agent (right), showing the flow of data and actions.
### Components/Axes
The diagram is divided into two primary sections connected by numbered arrows indicating process flow.
**Left Section: MLE-Bench (Competition Environment)**
* **Main Container:** A large, light green rounded rectangle labeled "MLE-Bench" on its left vertical edge.
* **Competition Box:** A smaller, darker green rounded rectangle inside the main container, labeled "Competition."
* **Description Sub-box:** Contains the text: "Train a model to achieve the highest accuracy..."
* **Dataset Sub-box:** Lists three files: `train.csv`, `test.csv`, `sample_submission.csv`.
* **Leaderboard Sub-box:** Contains three small icons (a gold trophy, a silver medal, a bronze medal).
* **Grader Box:** A white rounded rectangle below the Competition box, labeled "Grader."
* **Score Display:** To the left of the Grader box, a small element shows "Score: 63.4%" next to a gold medal icon.
**Right Section: Agent**
* **Main Container:** A dashed-line rounded rectangle labeled "Agent" at the top.
* **Thinking/Process Box:** A light purple rounded rectangle inside the Agent container.
* **Icon & Label:** A brain icon with the text "Thinking..."
* **Action List:** Four bullet-point style items: "Train model", "Test model", "Debug", "Create submission".
* **Output Box:** A solid purple rounded rectangle at the bottom of the Agent container, labeled `submission.csv`.
**Flow Arrows:**
* **Arrow 1:** A black arrow labeled "1" points from the "Dataset" sub-box in the Competition to the "Thinking..." box in the Agent.
* **Arrow 2:** A black arrow labeled "2" points from the `submission.csv` box in the Agent to the "Grader" box in the MLE-Bench.
### Detailed Analysis
The diagram outlines a clear, two-step cyclical process:
1. **Step 1 (Data Provision):** The MLE-Bench competition provides the dataset (`train.csv`, `test.csv`, `sample_submission.csv`) to the Agent. This is the input phase.
2. **Agent Processing:** The Agent performs a series of internal actions: training a model, testing it, debugging, and finally creating a submission file (`submission.csv`).
3. **Step 2 (Submission & Grading):** The Agent submits its `submission.csv` file to the Grader within the MLE-Bench environment.
4. **Feedback Loop:** The Grader evaluates the submission and produces a score (exemplified as 63.4%), which is then reflected on the Competition's Leaderboard. This completes one iteration of the workflow.
### Key Observations
* The process is explicitly numbered, emphasizing a sequential, two-stage interaction.
* The Agent's internal process ("Thinking...") is abstracted into four high-level tasks, suggesting it is an autonomous system handling the entire model development pipeline.
* The Grader is a separate component from the initial Competition description, highlighting its role as the evaluation engine.
* The score (63.4%) is shown with a gold medal icon, which may be an example or a placeholder, indicating that performance is quantified and ranked.
* The use of specific file names (`.csv`) grounds the abstract process in a common data science workflow format.
### Interpretation
This diagram models the core loop of an automated machine learning competition benchmark. It demonstrates how an AI agent is expected to interact with a standardized environment: receiving data, autonomously developing a solution, and submitting it for objective evaluation.
The separation between the "Competition" (defining the problem and data) and the "Grader" (providing the score) is a key architectural detail. It suggests the benchmark is designed to isolate the agent's performance from the problem definition, ensuring fair and repeatable evaluation.
The "MLE-Bench" label implies this is a benchmark suite, and the depicted workflow is a single task within it. The agent's listed actions ("Train," "Test," "Debug," "Create submission") encapsulate the entire machine learning development lifecycle, indicating the benchmark tests end-to-end capability, not just model training. The final score on the leaderboard represents the ultimate metric of success in this automated, self-contained research environment.