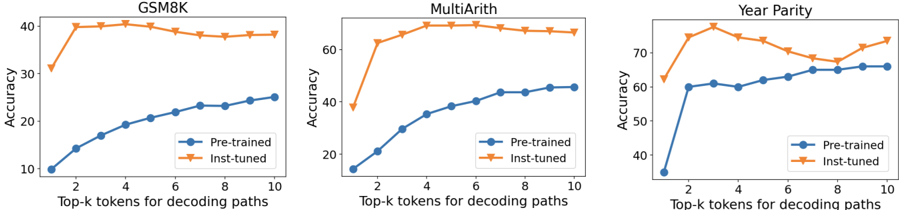
## Line Graphs: Model Accuracy vs. Top-k Tokens for Decoding Paths
### Overview
The image contains three line graphs comparing the accuracy of two model configurations ("Pre-trained" and "Inst-tuned") across three tasks: GSM8K, MultiArith, and Year Parity. Each graph plots accuracy against the number of top-k tokens used for decoding paths (k=2 to k=10).
### Components/Axes
- **X-axis**: "Top-k tokens for decoding paths" (values: 2, 4, 6, 8, 10)
- **Y-axis**: "Accuracy" (scales vary by task):
- GSM8K: 10–40
- MultiArith: 20–60
- Year Parity: 40–70
- **Legends**:
- Blue circles = Pre-trained
- Orange triangles = Inst-tuned
- **Graph Titles**:
- Top-left corner of each graph (e.g., "GSM8K", "MultiArith", "Year Parity")
### Detailed Analysis
#### GSM8K
- **Pre-trained**: Starts at ~10 (k=2), increases steadily to ~25 (k=10).
- **Inst-tuned**: Starts at ~30 (k=2), plateaus near ~38–40 (k=6–10).
- **Key Trend**: Inst-tuned outperforms pre-trained by ~20–30 points across all k.
#### MultiArith
- **Pre-trained**: Starts at ~10 (k=2), rises sharply to ~50 (k=10).
- **Inst-tuned**: Starts at ~40 (k=2), peaks at ~60 (k=4–6), then slightly declines to ~58 (k=10).
- **Key Trend**: Inst-tuned maintains ~10–20 point advantage over pre-trained, with diminishing returns at higher k.
#### Year Parity
- **Pre-trained**: Starts at ~30 (k=2), increases sharply to ~60 (k=10).
- **Inst-tuned**: Starts at ~60 (k=2), dips to ~50 (k=8), then rises to ~70 (k=10).
- **Key Trend**: Inst-tuned shows volatility but ends with ~10–20 point advantage over pre-trained.
### Key Observations
1. **Inst-tuned models consistently outperform pre-trained models** across all tasks and k values.
2. **Pre-trained models show linear improvement** with increasing k in all tasks.
3. **Inst-tuned models exhibit plateauing or volatility** at higher k values (e.g., MultiArith at k=10, Year Parity at k=8).
4. **Year Parity** has the highest absolute accuracy values (~70) compared to other tasks.
### Interpretation
The data suggests that **inst-tuned models** are more robust to decoding path variability (higher k) but may suffer from overfitting or instability at extreme k values (e.g., Year Parity's dip at k=8). **Pre-trained models** benefit predictably from larger k but lack the optimization of inst-tuned variants. The **Year Parity task** demonstrates the largest performance gap between configurations, implying task-specific architectural or training differences. The trends align with expectations for fine-tuned models (inst-tuned) outperforming base models (pre-trained) but highlight trade-offs in generalization vs. specialization.