TECHNICAL ASSET FINGERPRINT
0865e482ce4057ec09639acb
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
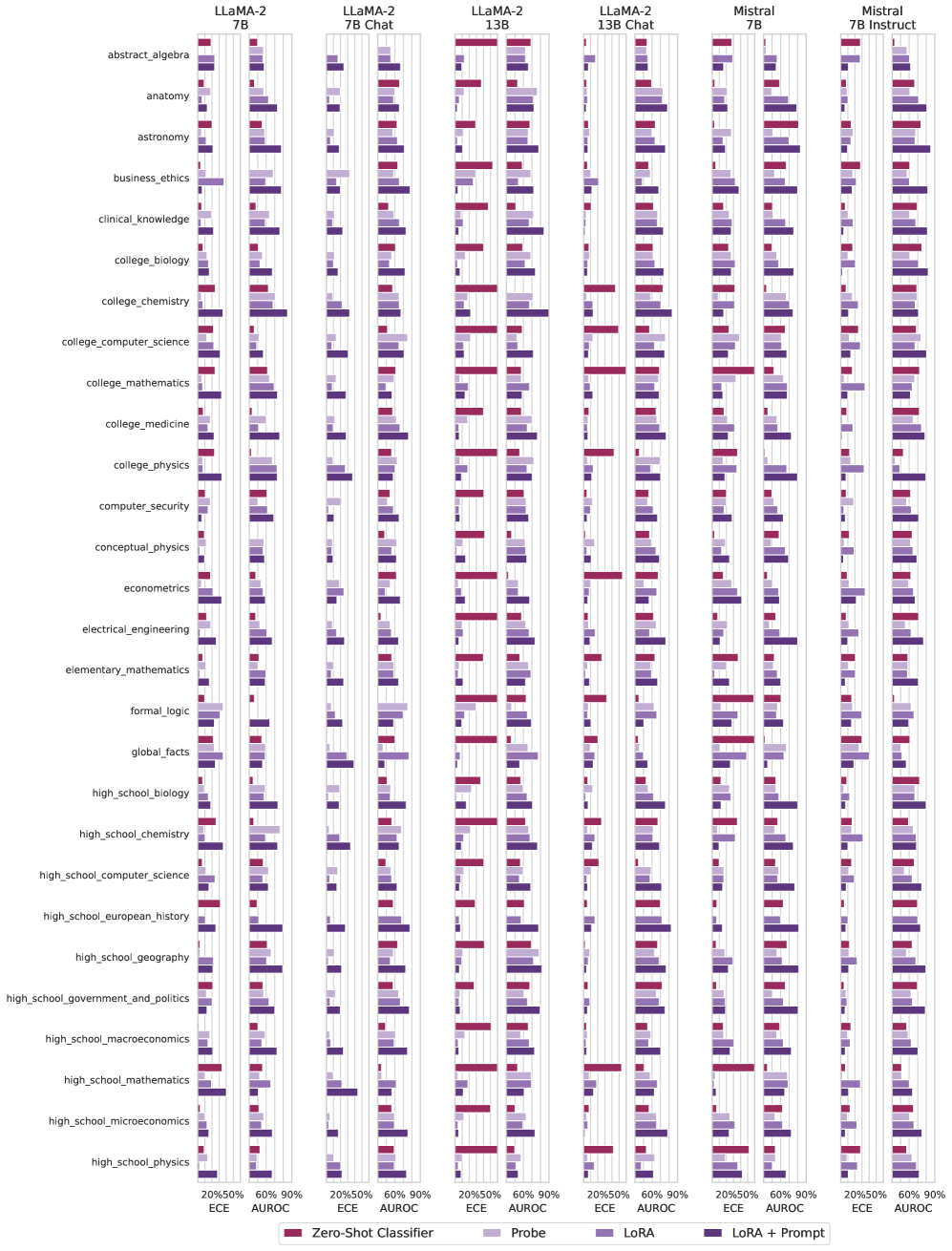
## Grouped Bar Chart: Language Model Performance Across Academic Subjects
### Overview
This image is a complex, multi-panel grouped bar chart comparing the performance of six different Large Language Model (LLM) variants across 28 academic subjects. Performance is measured using two metrics: Expected Calibration Error (ECE) and Area Under the Receiver Operating Characteristic curve (AUROC). Each model's performance is evaluated using four different methods, represented by distinct colors.
### Components/Axes
**1. Top Header (Model Columns):**
Six vertical columns, each representing a different LLM variant. From left to right:
- `LLaMA-2 7B`
- `LLaMA-2 7B Chat`
- `LLaMA-2 13B`
- `LLaMA-2 13B Chat`
- `Mistral 7B`
- `Mistral 7B Instruct`
**2. Left Vertical Axis (Subject Categories):**
A list of 28 academic subjects, ordered from top to bottom. The full list is:
`abstract_algebra`, `anatomy`, `astronomy`, `business_ethics`, `clinical_knowledge`, `college_biology`, `college_chemistry`, `college_computer_science`, `college_mathematics`, `college_medicine`, `college_physics`, `computer_security`, `conceptual_physics`, `econometrics`, `electrical_engineering`, `elementary_mathematics`, `formal_logic`, `global_facts`, `high_school_biology`, `high_school_chemistry`, `high_school_computer_science`, `high_school_european_history`, `high_school_geography`, `high_school_government_and_politics`, `high_school_macroeconomics`, `high_school_mathematics`, `high_school_microeconomics`, `high_school_physics`.
**3. Bottom Horizontal Axis (Metrics):**
Each of the six model columns has its own x-axis at the bottom, labeled with two metrics:
- `ECE` (Expected Calibration Error) - Scale: 20%, 50%, 90% (lower is better).
- `AUROC` (Area Under the ROC Curve) - Scale: 20%, 50%, 90% (higher is better).
**4. Legend (Bottom Center):**
Four colored squares with labels, defining the evaluation methods:
- **Red Square:** `Zero-Shot Classifier`
- **Light Purple Square:** `Probe`
- **Medium Purple Square:** `LoRA`
- **Dark Purple Square:** `LoRA + Prompt`
**5. Chart Structure:**
For each of the 28 subjects within each of the 6 model columns, there are two small grouped bar clusters:
- The left cluster shows the `ECE` value for the four methods.
- The right cluster shows the `AUROC` value for the four methods.
The bars are horizontal, extending from a central baseline. The length of the bar corresponds to the metric value.
### Detailed Analysis
**Trend Verification & Data Extraction (Approximate Values):**
The chart is dense with data. A precise point-by-point extraction is not feasible, but clear trends and representative values can be identified.
*General Pattern Across Models:*
- **ECE (Left Cluster):** The `Zero-Shot Classifier` (red) consistently shows the shortest bars (lowest ECE, best calibration) across most subjects and models. The `Probe` (light purple) often has the longest bars (highest ECE, worst calibration). `LoRA` and `LoRA + Prompt` (medium and dark purple) typically fall in between.
- **AUROC (Right Cluster):** The pattern often reverses. `LoRA + Prompt` (dark purple) frequently shows the longest bars (highest AUROC, best discriminative performance), followed closely by `LoRA` (medium purple). `Zero-Shot Classifier` (red) and `Probe` (light purple) generally have shorter bars (lower AUROC).
*Model-Specific Observations:*
- **LLaMA-2 7B vs. 7B Chat:** The Chat variant generally shows slightly improved AUROC scores (longer dark/medium purple bars) across many subjects, with a similar ECE pattern.
- **LLaMA-2 13B vs. 13B Chat:** Similar to the 7B pair, the Chat variant shows a modest performance boost in AUROC. The 13B models, in general, have slightly longer AUROC bars than their 7B counterparts.
- **Mistral 7B vs. 7B Instruct:** The Instruct variant shows a more pronounced improvement in AUROC over the base Mistral 7B, especially for `LoRA + Prompt`. The ECE for `Zero-Shot Classifier` remains very low.
*Subject-Specific Outliers:*
- **`college_computer_science`:** For `LLaMA-2 13B`, the `Zero-Shot Classifier` (red) AUROC bar is exceptionally long, nearing 90%, significantly outperforming other methods for that model/subject combination.
- **`formal_logic`:** Across most models, the AUROC scores are relatively low (bars are short), suggesting this is a challenging subject for all tested models.
- **`high_school_mathematics`:** Shows a very clear stratification: `LoRA + Prompt` (dark purple) has the highest AUROC, followed by `LoRA`, then `Probe`, with `Zero-Shot` lowest. The ECE shows the inverse order.
### Key Observations
1. **Method Trade-off:** There is a clear and consistent trade-off between calibration (ECE) and discriminative performance (AUROC). The `Zero-Shot Classifier` is best calibrated but has lower AUROC. `LoRA + Prompt` achieves the highest AUROC but often at the cost of worse calibration (higher ECE).
2. **Impact of Instruction Tuning:** For both LLaMA-2 and Mistral, the "Chat" or "Instruct" variants consistently improve AUROC scores, particularly when using the `LoRA + Prompt` method, indicating fine-tuning for instruction following boosts task performance.
3. **Scale Benefit:** The 13B LLaMA-2 models generally outperform the 7B models on AUROC, demonstrating a benefit from increased model scale.
4. **Subject Difficulty:** Subjects like `formal_logic`, `abstract_algebra`, and `econometrics` tend to have shorter AUROC bars across the board, indicating they are more difficult for these models. Subjects like `high_school_biology` and `clinical_knowledge` show higher overall AUROC scores.
### Interpretation
This chart provides a multifaceted evaluation of LLM capabilities, moving beyond simple accuracy to examine calibration and performance across diverse knowledge domains.
**What the Data Suggests:**
- **No Single Best Method:** The choice of evaluation method (`Zero-Shot`, `Probe`, `LoRA`, `LoRA + Prompt`) involves a fundamental trade-off. If reliable confidence estimates are critical (low ECE), a `Zero-Shot Classifier` may be preferable. If maximizing discriminative power (high AUROC) is the goal, `LoRA + Prompt` is superior.
- **The Value of Specialization:** The superior AUROC of `LoRA` and `LoRA + Prompt` methods suggests that adapting the model to the specific task (via parameter-efficient fine-tuning) yields better performance than generic probing or zero-shot approaches. Adding prompt engineering (`LoRA + Prompt`) provides an additional boost.
- **Instruction Tuning is Effective:** The consistent improvement of Chat/Instruct models indicates that alignment training generalizes well, enhancing performance on a wide array of academic multiple-choice questions, not just conversational tasks.
**Underlying Implications:**
The data implicitly argues for a more nuanced approach to model evaluation. A model's "performance" is not a single number but a profile across metrics and methods. For real-world deployment, one must decide whether calibration or raw discriminative ability is more important. Furthermore, the results validate the use of parameter-efficient fine-tuning (LoRA) combined with prompt engineering as a powerful strategy for adapting foundation models to specialized knowledge tasks, outperforming both out-of-the-box usage and simpler probing techniques. The persistent difficulty of formal logic and abstract mathematics subjects highlights a current frontier in LLM reasoning capabilities.
DECODING INTELLIGENCE...