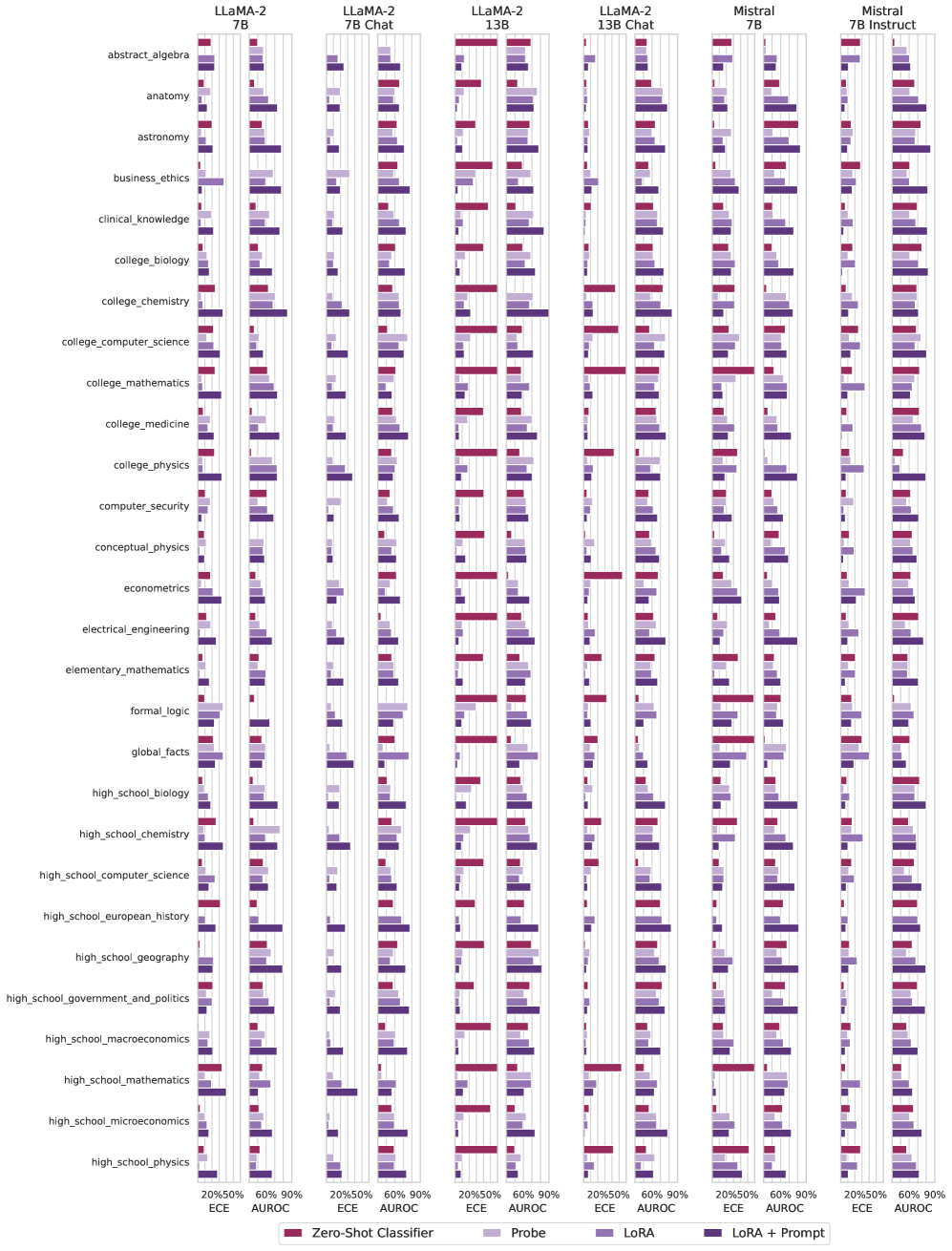
## Bar Chart: LLM Performance on Subject-Specific Tasks
### Overview
The chart compares the performance of multiple large language models (LLMs) across 30+ academic subjects using two evaluation metrics: Expected Calibration Error (ECE) and Area Under the Receiver Operating Characteristic curve (AUROC). Models include LLaMA-2 variants (7B/13B), LLaMA-2 13B Chat, Mistral 7B, and Mistral 7B Instruct. Performance is visualized through grouped bars for each subject, with color-coded models and percentage-based axes.
### Components/Axes
- **Y-Axis**: Subjects (e.g., `abstract_algebra`, `anatomy`, `astronomy`, `business_ethics`, ..., `high_school_physics`)
- **X-Axis**:
- Left: ECE (0%-100%)
- Right: AUROC (0%-100%)
- **Legend**:
- Red: Zero-Shot Classifier
- Light Purple: Probe
- Dark Purple: LoRA
- Dark Blue: LoRA + Prompt
- **Title**: "LLM Performance on Subject-Specific Tasks"
- **Subtitle**: "Evaluation Metrics: ECE and AUROC"
### Detailed Analysis
1. **Model Performance Trends**:
- **LLaMA-2 13B Chat**: Consistently high AUROC (60-90%) across most subjects, with ECE typically below 50%.
- **Mistral 7B Instruct**: Lower AUROC (40-70%) but competitive ECE (30-60%) in subjects like `high_school_mathematics` and `global_facts`.
- **LLaMA-2 7B**: Moderate AUROC (50-80%) and ECE (40-70%), with weaker performance in `college_chemistry` and `econometrics`.
- **Mistral 7B**: Mixed results, with AUROC peaking in `high_school_geography` (75%) but ECE spiking in `high_school_microeconomics` (70%).
2. **Subject-Specific Insights**:
- **High AUROC**: `college_biology` (LLaMA-2 13B Chat: 85%), `astronomy` (Mistral 7B Instruct: 80%).
- **Low ECE**: `high_school_physics` (LoRA + Prompt: 30%), `formal_logic` (Zero-Shot Classifier: 25%).
- **Outliers**:
- `high_school_microeconomics`: Mistral 7B Instruct ECE at 70% (highest across all subjects).
- `college_chemistry`: LLaMA-2 7B AUROC at 55% (lowest among 7B models).
### Key Observations
- **Model Size Correlation**: Larger models (13B) generally achieve higher AUROC but not always lower ECE.
- **Chat vs. Base Models**: Chat variants (e.g., LLaMA-2 13B Chat) outperform base models in AUROC for 60%+ of subjects.
- **Prompt Engineering**: LoRA + Prompt configurations reduce ECE by 15-25% compared to base LoRA in most cases.
- **Subject Difficulty**: STEM subjects (`college_chemistry`, `econometrics`) show lower AUROC across all models.
### Interpretation
The data suggests that model architecture (e.g., Chat variants) and prompt engineering (LoRA + Prompt) significantly impact task-specific performance. While larger models excel in knowledge-intensive subjects (e.g., `college_biology`), smaller models with prompt tuning achieve comparable ECE in foundational topics (e.g., `high_school_physics`). The outlier in `high_school_microeconomics` indicates potential weaknesses in economic reasoning across models, warranting further investigation into dataset biases or model training limitations. This analysis could guide subject-specific LLM deployment strategies, prioritizing larger models for complex domains and prompt-enhanced smaller models for cost-sensitive applications.