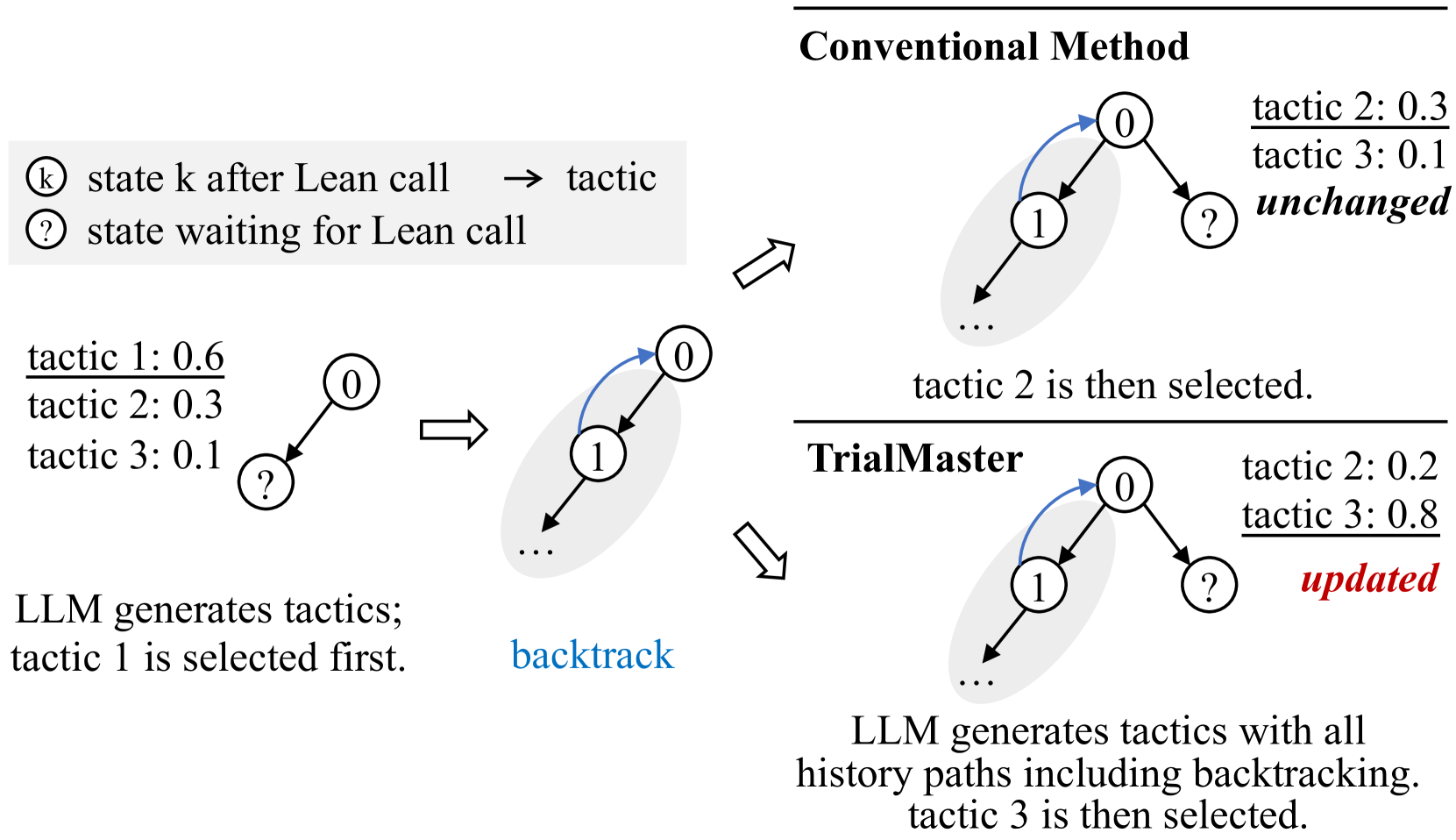
## Diagram: Comparison of Conventional Method vs TrialMaster for Tactic Selection
### Overview
The diagram compares two approaches for selecting tactics in a decision-making process: the Conventional Method and the TrialMaster method. It illustrates how tactics are generated, probabilities are assigned, and backtracking influences outcomes. The Conventional Method uses static probabilities, while TrialMaster incorporates backtracking to update probabilities dynamically.
### Components/Axes
- **Left Flowchart (Conventional Method)**:
- **Nodes**:
- State `k` after Lean call → tactic selection.
- State waiting for Lean call.
- Tactics with probabilities:
- Tactic 1: 0.6
- Tactic 2: 0.3
- Tactic 3: 0.1
- A question mark (`?`) node representing uncertainty.
- **Flow**:
- Arrows indicate progression from state `k` to tactic selection.
- Backtracking arrow (blue) loops from node `1` to `0`.
- Final selection of tactic 2 (0.3) after backtracking.
- **Right Flowchart (TrialMaster)**:
- **Nodes**:
- Similar structure but with updated probabilities:
- Tactic 2: 0.2
- Tactic 3: 0.8
- A question mark (`?`) node.
- **Flow**:
- Arrows show progression with backtracking included in history.
- Final selection of tactic 3 (0.8).
- **Text Elements**:
- Labels: "unchanged" (Conventional Method), "updated" (TrialMaster).
- Descriptions:
- "LLM generates tactics; tactic 1 is selected first."
- "LLM generates tactics with all history paths including backtracking."
### Detailed Analysis
- **Conventional Method**:
- Initial probabilities: Tactic 1 (0.6), Tactic 2 (0.3), Tactic 3 (0.1).
- After backtracking, tactic 2 is selected despite its lower initial probability (0.3).
- No dynamic updates; probabilities remain static.
- **TrialMaster**:
- Probabilities are updated based on backtracking history:
- Tactic 2: 0.2 (reduced from 0.3).
- Tactic 3: 0.8 (increased from 0.1).
- Backtracking is explicitly included in the LLM's history, leading to a shift in selection toward tactic 3.
### Key Observations
1. **Probability Shifts**: TrialMaster dynamically adjusts probabilities using backtracking, while the Conventional Method uses fixed values.
2. **Selection Outcomes**:
- Conventional Method selects tactic 2 (0.3) after backtracking.
- TrialMaster selects tactic 3 (0.8) due to updated probabilities.
3. **Backtracking Impact**: The inclusion of backtracking in TrialMaster significantly alters tactic selection, favoring higher-probability options over time.
### Interpretation
The diagram highlights the advantages of the TrialMaster method over the Conventional Method. By incorporating backtracking, TrialMaster leverages historical data to refine tactic probabilities, leading to more informed decisions. The Conventional Method's static probabilities fail to adapt, resulting in suboptimal selections (e.g., tactic 2 at 0.3 vs. tactic 3 at 0.8 in TrialMaster). This suggests that dynamic, context-aware systems (like TrialMaster) outperform rigid frameworks in complex decision-making scenarios. The use of backtracking as a feedback mechanism is critical for optimizing outcomes in iterative processes.