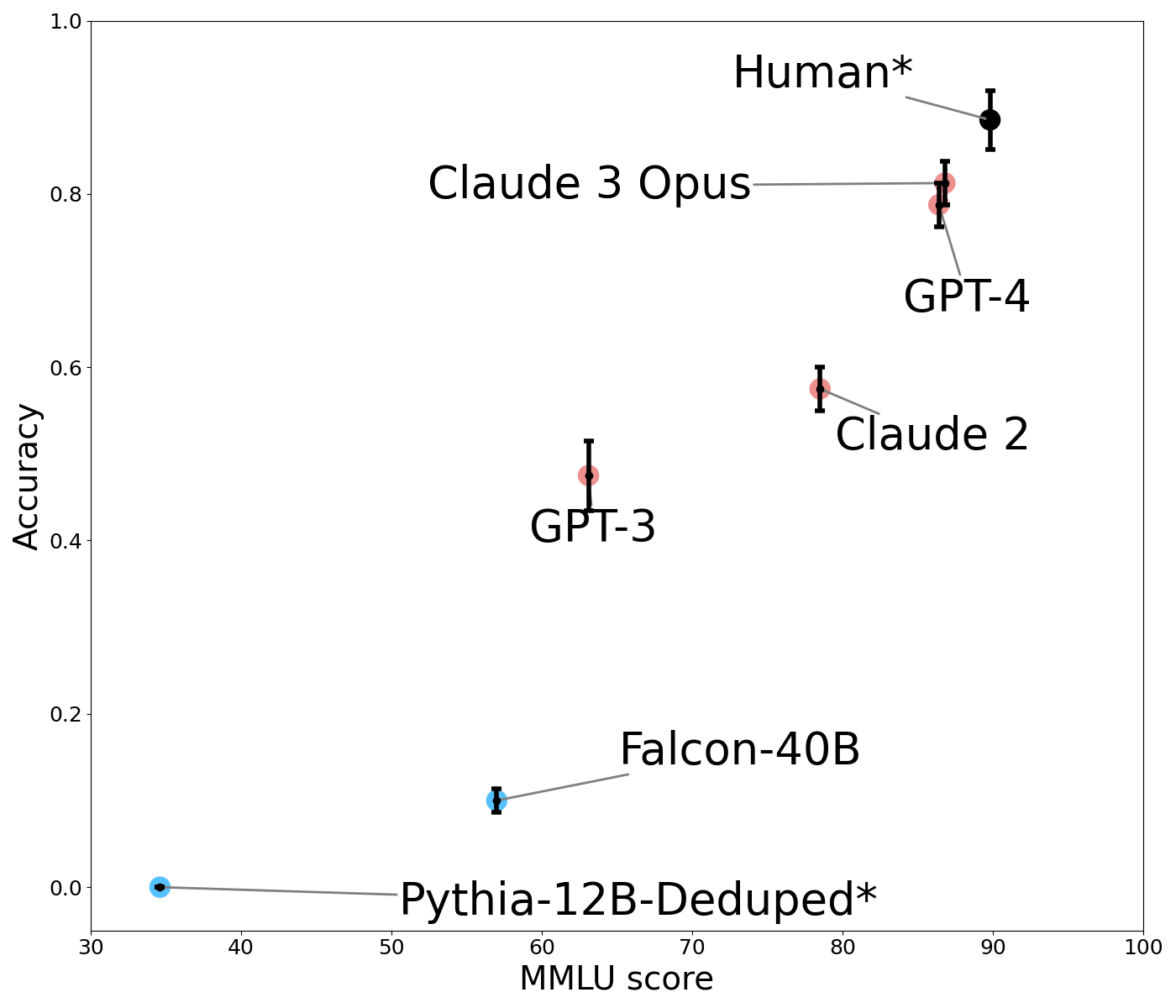
## Chart: Model Accuracy vs. MMLU Score
### Overview
The image is a scatter plot comparing the accuracy of several language models against their MMLU (Massive Multitask Language Understanding) score. The plot displays data points for different models, with error bars indicating the uncertainty in their accuracy. The models include Human, Claude 3 Opus, GPT-4, Claude 2, GPT-3, Falcon-40B, and Pythia-12B-Deduped.
### Components/Axes
* **X-axis:** MMLU score, ranging from 30 to 100.
* **Y-axis:** Accuracy, ranging from 0.0 to 1.0.
* **Data Points:** Each data point represents a language model.
* Human*: Black data point with error bars. Located at approximately (92, 0.9).
* Claude 3 Opus: Red data point with error bars. Located at approximately (87, 0.8).
* GPT-4: Red data point with error bars. Located at approximately (88, 0.75).
* Claude 2: Red data point with error bars. Located at approximately (80, 0.58).
* GPT-3: Red data point with error bars. Located at approximately (60, 0.5).
* Falcon-40B: Blue data point with error bars. Located at approximately (65, 0.1).
* Pythia-12B-Deduped*: Cyan data point with error bars. Located at approximately (35, 0.0).
* **Error Bars:** Vertical lines extending above and below each data point, representing the uncertainty in the accuracy measurement.
* **Labels:** Text labels identifying each data point (language model). Gray lines connect the data points to their labels.
### Detailed Analysis
* **Human*:** The "Human*" data point is located at the top-right of the plot, indicating high accuracy and a high MMLU score. The approximate coordinates are (92, 0.9).
* **Claude 3 Opus:** Located near the top, with an MMLU score around 87 and an accuracy of approximately 0.8.
* **GPT-4:** Positioned slightly below Claude 3 Opus, with an MMLU score around 88 and an accuracy of approximately 0.75.
* **Claude 2:** Located in the middle of the plot, with an MMLU score around 80 and an accuracy of approximately 0.58.
* **GPT-3:** Positioned to the left of Claude 2, with an MMLU score around 60 and an accuracy of approximately 0.5.
* **Falcon-40B:** Located near the bottom, with an MMLU score around 65 and an accuracy of approximately 0.1.
* **Pythia-12B-Deduped*:** Located at the bottom-left of the plot, indicating low accuracy and a low MMLU score. The approximate coordinates are (35, 0.0).
### Key Observations
* There is a general trend of increasing accuracy with increasing MMLU score.
* The "Human*" data point represents a performance ceiling, with the highest accuracy and MMLU score.
* The models Claude 3 Opus and GPT-4 are close in performance, both having high accuracy and MMLU scores.
* Falcon-40B and Pythia-12B-Deduped* have significantly lower accuracy and MMLU scores compared to the other models.
### Interpretation
The plot illustrates the relationship between a language model's ability to understand and perform multiple tasks (MMLU score) and its overall accuracy. The data suggests that models with higher MMLU scores tend to have higher accuracy. The "Human*" data point serves as a benchmark, indicating the potential upper limit of performance. The relative positions of the other models provide a comparison of their capabilities, with Claude 3 Opus and GPT-4 demonstrating strong performance, while Falcon-40B and Pythia-12B-Deduped* show comparatively weaker performance. The error bars indicate the variability in the accuracy measurements, which should be considered when comparing the models.