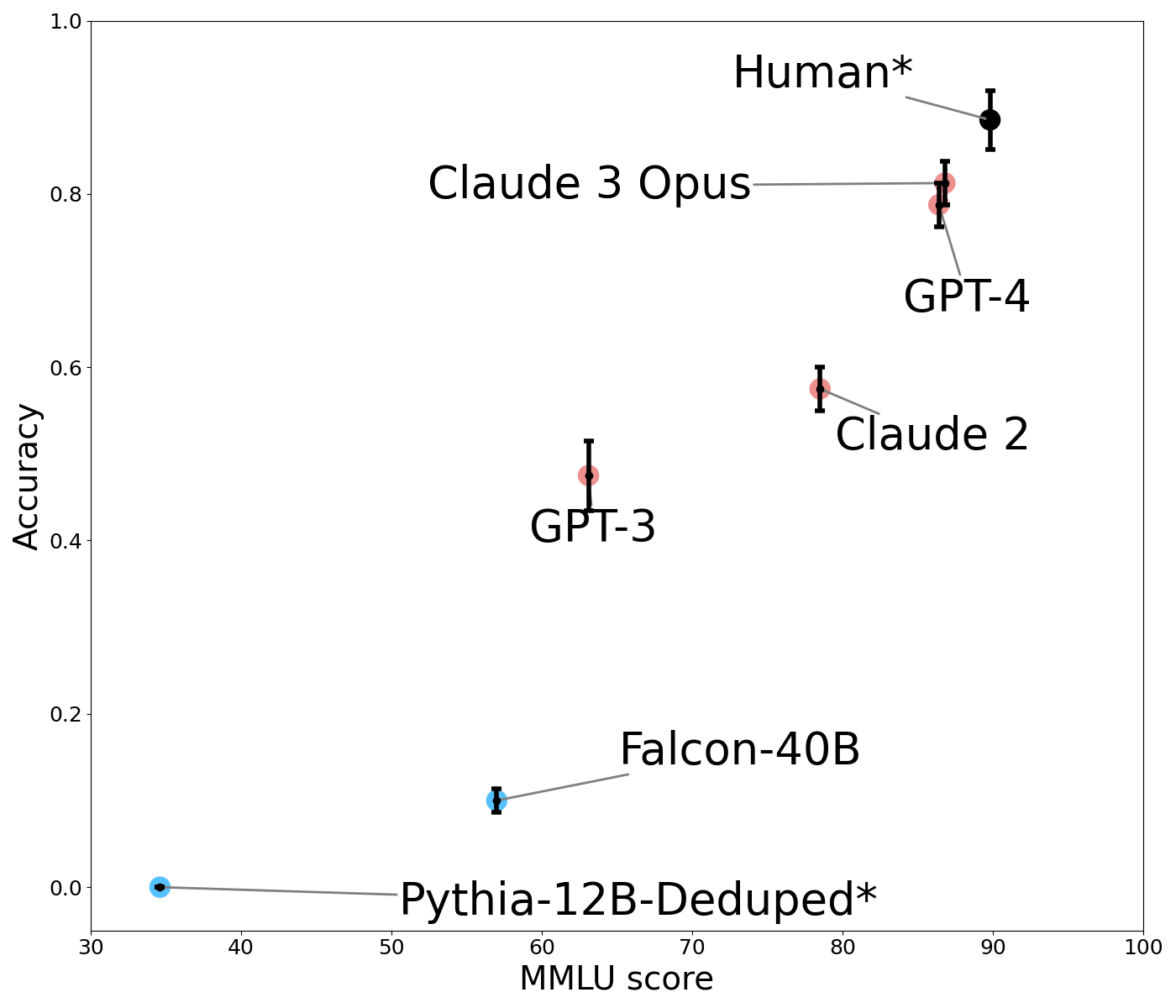
## Scatter Plot: Model Performance Comparison
### Overview
The image is a scatter plot comparing the accuracy of various AI models against their MMLU (Massive Multitask Language Understanding) scores. The plot includes error bars for each data point, indicating variability or confidence intervals. The models are labeled with their names and colors, with a legend on the right.
### Components/Axes
- **X-axis**: MMLU score (ranging from 30 to 100, labeled "MMLU score").
- **Y-axis**: Accuracy (ranging from 0.0 to 1.0, labeled "Accuracy").
- **Legend**: Located on the right, associating colors with models:
- **Black**: Human*
- **Red**: Claude 3 Opus, GPT-4, Claude 2
- **Blue**: GPT-3, Falcon-40B, Pythia-12B-Deduped*
### Detailed Analysis
1. **Human***
- **Position**: Top-right corner.
- **Accuracy**: ~0.9 (highest).
- **MMLU Score**: ~95.
- **Error Bars**: Smallest, indicating high confidence.
2. **Claude 3 Opus**
- **Position**: Near Human*, slightly lower.
- **Accuracy**: ~0.8.
- **MMLU Score**: ~85.
- **Error Bars**: Moderate.
3. **GPT-4**
- **Position**: Slightly below Claude 3 Opus.
- **Accuracy**: ~0.78.
- **MMLU Score**: ~80.
- **Error Bars**: Similar to Claude 3 Opus.
4. **Claude 2**
- **Position**: Mid-right.
- **Accuracy**: ~0.55.
- **MMLU Score**: ~70.
- **Error Bars**: Larger than Claude 3 Opus/GPT-4.
5. **GPT-3**
- **Position**: Mid-left.
- **Accuracy**: ~0.45.
- **MMLU Score**: ~55.
- **Error Bars**: Moderate.
6. **Falcon-40B**
- **Position**: Lower-left.
- **Accuracy**: ~0.1.
- **MMLU Score**: ~40.
- **Error Bars**: Large.
7. **Pythia-12B-Deduped***
- **Position**: Bottom-left.
- **Accuracy**: ~0.0 (near zero).
- **MMLU Score**: ~30.
- **Error Bars**: Largest, indicating high variability.
### Key Observations
- **Human* outperforms all models** in both accuracy and MMLU score.
- **Claude 3 Opus and GPT-4** are the closest to Human*, with Claude 3 Opus having a slight edge in accuracy despite a lower MMLU score.
- **Red-colored models** (Claude and GPT variants) generally outperform blue-colored models (GPT-3, Falcon-40B, Pythia).
- **Pythia-12B-Deduped*** has the lowest accuracy and MMLU score, with the largest error bars, suggesting instability or poor generalization.
- **Positive correlation** between MMLU score and accuracy, but exceptions exist (e.g., GPT-4 has a lower MMLU than Claude 3 Opus but similar accuracy).
### Interpretation
The data suggests that **MMLU score is a strong predictor of model performance**, but not the sole factor. Human* serves as the gold standard, while Claude 3 Opus and GPT-4 demonstrate near-human capabilities. The red models (Claude and GPT) appear more efficient or optimized for accuracy compared to blue models. Pythia-12B-Deduped*’s near-zero accuracy may stem from its "deduped" training data, which could reduce its ability to generalize. The error bars highlight variability in performance, with Pythia showing the least reliability. This plot underscores the trade-offs between model size, training data quality, and real-world applicability.