## Pie Charts: Errors in GPT-4o and Claude Opus (Search and Read w/ Demo)
### Overview
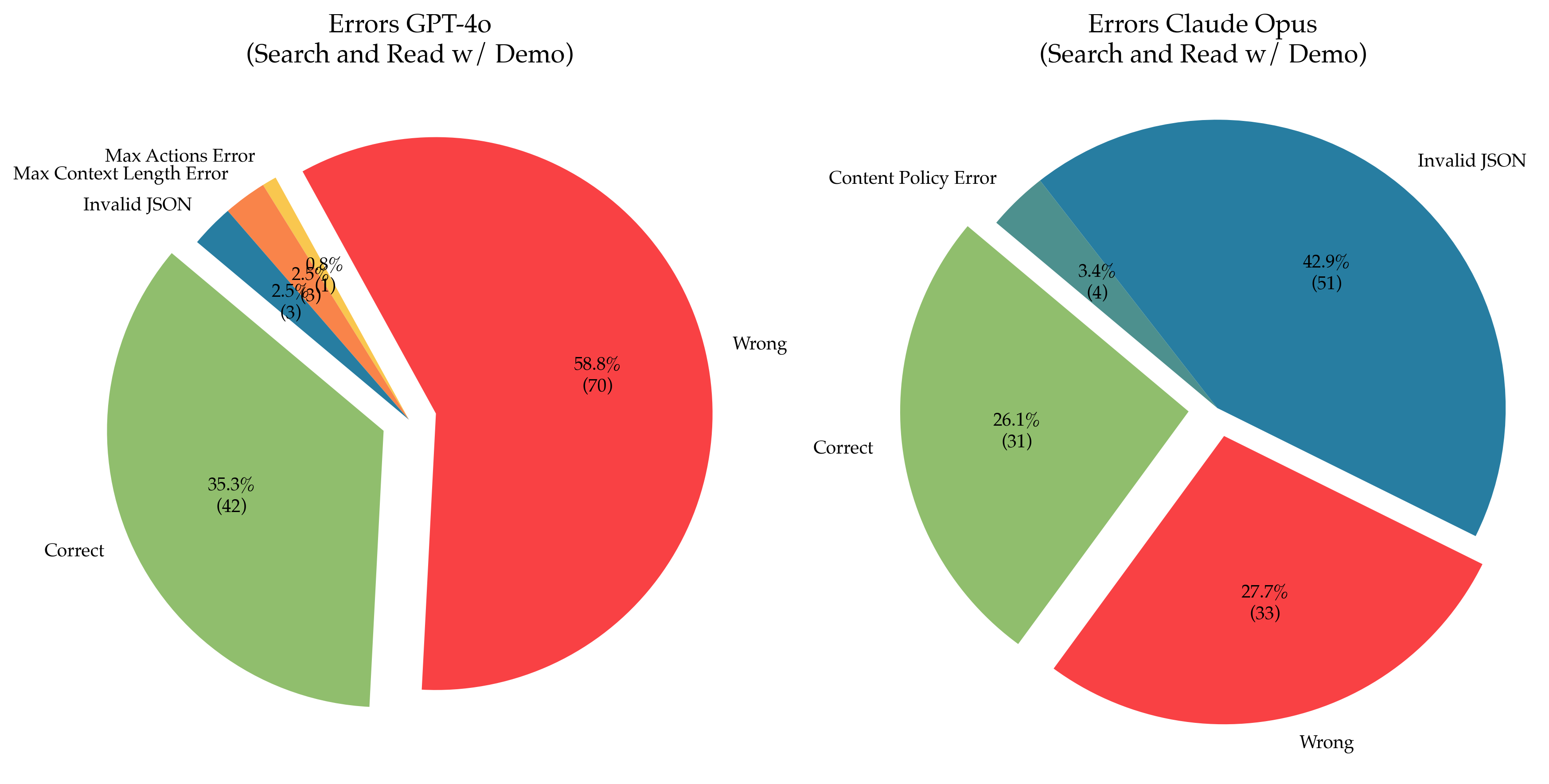
The image presents two pie charts comparing the types of errors encountered by GPT-4o and Claude Opus during a "Search and Read w/ Demo" task. Each chart breaks down the errors into categories, displaying both the percentage and the number of occurrences for each category.
### Components/Axes
**Left Pie Chart: Errors GPT-4o (Search and Read w/ Demo)**
* **Title:** Errors GPT-4o (Search and Read w/ Demo)
* **Categories:**
* Wrong (Red)
* Correct (Light Green)
* Invalid JSON (Dark Blue)
* Max Context Length Error (Orange)
* Max Actions Error (Yellow)
**Right Pie Chart: Errors Claude Opus (Search and Read w/ Demo)**
* **Title:** Errors Claude Opus (Search and Read w/ Demo)
* **Categories:**
* Invalid JSON (Dark Blue)
* Wrong (Red)
* Correct (Light Green)
* Content Policy Error (Dark Green)
### Detailed Analysis
**Left Pie Chart: Errors GPT-4o**
* **Wrong (Red):** 58.8% (70)
* **Correct (Light Green):** 35.3% (42)
* **Invalid JSON (Dark Blue):** 2.5% (3)
* **Max Context Length Error (Orange):** 2.5% (3)
* **Max Actions Error (Yellow):** 0.8% (1)
**Right Pie Chart: Errors Claude Opus**
* **Invalid JSON (Dark Blue):** 42.9% (51)
* **Wrong (Red):** 27.7% (33)
* **Correct (Light Green):** 26.1% (31)
* **Content Policy Error (Dark Green):** 3.4% (4)
### Key Observations
* GPT-4o has a significantly higher percentage of "Wrong" responses (58.8%) compared to Claude Opus (27.7%).
* Claude Opus has a much larger percentage of "Invalid JSON" errors (42.9%) compared to GPT-4o (2.5%).
* GPT-4o exhibits "Max Context Length Error" and "Max Actions Error," which are not present in Claude Opus's error distribution.
* Claude Opus has "Content Policy Error," which is not present in GPT-4o's error distribution.
* The percentage of "Correct" responses is higher for GPT-4o (35.3%) than for Claude Opus (26.1%).
### Interpretation
The pie charts reveal distinct error profiles for GPT-4o and Claude Opus in the "Search and Read w/ Demo" task. GPT-4o struggles more with providing correct responses, resulting in a higher "Wrong" percentage. Claude Opus, on the other hand, frequently encounters issues with "Invalid JSON," suggesting potential problems in its data handling or output formatting. The presence of "Max Context Length Error" and "Max Actions Error" in GPT-4o indicates limitations in its ability to handle complex or lengthy tasks. The "Content Policy Error" in Claude Opus suggests that it may be more sensitive to certain types of content, leading to rejections or errors. Overall, the data suggests that GPT-4o and Claude Opus have different strengths and weaknesses in this specific task, with GPT-4o being more prone to incorrect answers and Claude Opus struggling with JSON formatting and content policy restrictions.