\n
## Pie Charts: Error Analysis of GPT-4o and Claude Opus
### Overview
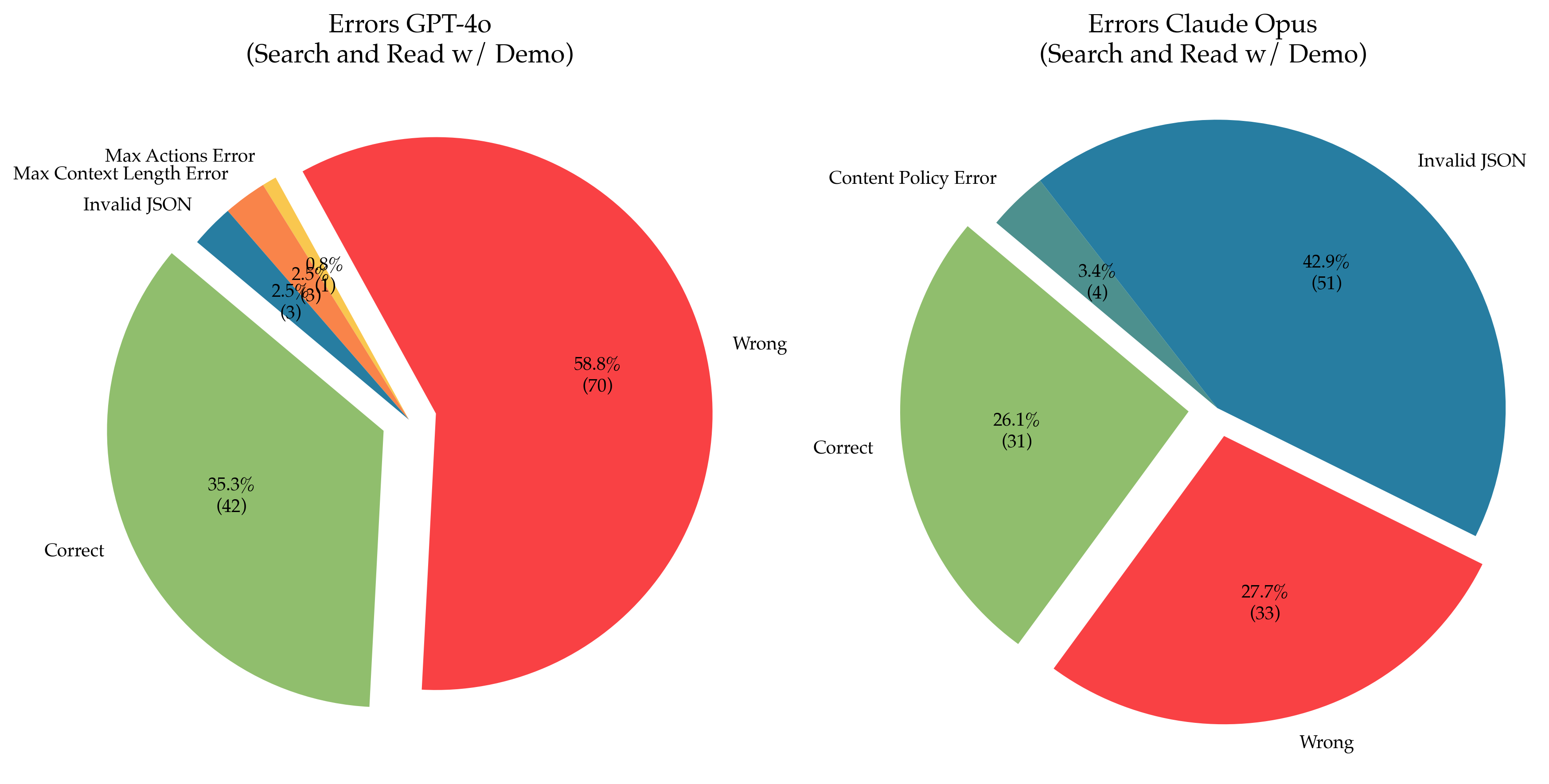
The image presents two pie charts side-by-side, comparing the error types of GPT-4o and Claude Opus models during a "Search and Read w/ Demo" evaluation. Each chart visualizes the distribution of different error categories as percentages and absolute counts.
### Components/Axes
Each pie chart has the following components:
* **Title:** Indicates the model being analyzed ("Errors GPT-4o (Search and Read w/ Demo)" and "Errors Claude Opus (Search and Read w/ Demo)").
* **Slices:** Represent different error types.
* **Labels:** Each slice is labeled with the error type and its percentage of the total errors, along with the absolute count in parentheses.
* **Color Coding:** Each error type is assigned a distinct color for visual differentiation.
### Detailed Analysis or Content Details
**GPT-4o Errors (Left Chart):**
* **Correct:** 35.3% (42) - Represented by a light green slice.
* **Wrong:** 58.8% (70) - Represented by a red slice.
* **Max Actions Error:** 2.5% (3) - Represented by a light blue slice.
* **Max Context Length Error:** 2.5% (3) - Represented by a yellow slice.
* **Invalid JSON:** 0.8% (1) - Represented by a pink slice.
**Claude Opus Errors (Right Chart):**
* **Correct:** 26.1% (31) - Represented by a light green slice.
* **Wrong:** 27.7% (33) - Represented by a red slice.
* **Invalid JSON:** 42.9% (51) - Represented by a dark grey slice.
* **Content Policy Error:** 3.4% (4) - Represented by a teal slice.
### Key Observations
* GPT-4o has a higher percentage of "Wrong" answers (58.8%) compared to Claude Opus (27.7%).
* Claude Opus has a significantly higher percentage of "Invalid JSON" errors (42.9%) than GPT-4o (0.8%).
* GPT-4o has a more even distribution of errors across different categories (Max Actions, Max Context Length, Invalid JSON) compared to Claude Opus.
* Both models have a substantial portion of errors categorized as "Wrong".
* The "Correct" responses are higher for GPT-4o (35.3%) than for Claude Opus (26.1%).
### Interpretation
The data suggests that GPT-4o, while making more incorrect responses overall, exhibits a more diverse range of error types. Claude Opus, on the other hand, struggles significantly with generating valid JSON, which constitutes the majority of its errors. This could indicate differences in the models' architectures, training data, or specific strengths and weaknesses in handling structured data formats. The higher percentage of "Wrong" answers for both models suggests a need for improvement in their reasoning and factual accuracy during search and read tasks. The "Content Policy Error" for Claude Opus, while small, indicates potential issues with adhering to safety guidelines. The difference in the "Correct" response rate suggests GPT-4o performs better overall in this specific "Search and Read w/ Demo" evaluation. The absolute counts provide context to the percentages, showing that the evaluation involved a reasonable number of samples (totaling 112 for GPT-4o and 119 for Claude Opus).