\n
## Comparative Error Analysis: GPT-4o vs. Claude Opus
### Overview
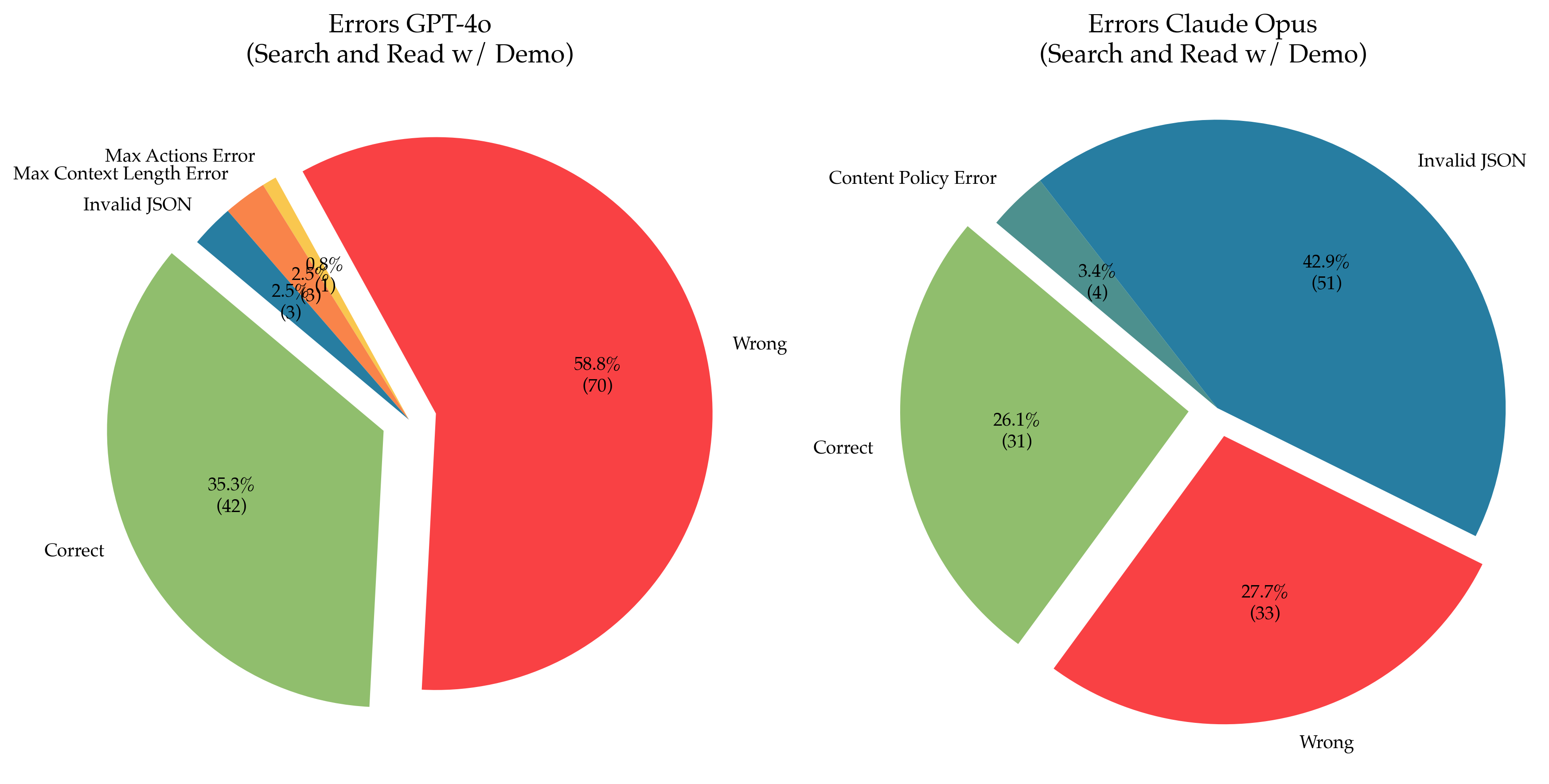
The image displays two pie charts side-by-side, comparing the error distributions of two AI models, GPT-4o and Claude Opus, on a "Search and Read w/ Demo" task. Each chart breaks down the outcomes into categories of correct responses and various error types, showing both percentage and absolute count (in parentheses).
### Components/Axes
* **Chart Type:** Two exploded pie charts.
* **Titles:**
* Left Chart: "Errors GPT-4o (Search and Read w/ Demo)"
* Right Chart: "Errors Claude Opus (Search and Read w/ Demo)"
* **Data Series (Categories):** The categories are consistent across both charts, represented by distinct colors:
* **Correct** (Light Green)
* **Wrong** (Red)
* **Invalid JSON** (Blue)
* **Max Context Length Error** (Orange) - *Only present in GPT-4o chart.*
* **Max Actions Error** (Yellow) - *Only present in GPT-4o chart.*
* **Content Policy Error** (Teal) - *Only present in Claude Opus chart.*
* **Spatial Layout:** The two charts are positioned horizontally. The legend is integrated directly as labels pointing to their respective slices. Slices are "exploded" (separated from the center) for emphasis.
### Detailed Analysis
#### **Chart 1: Errors GPT-4o (Left)**
* **Wrong (Red):** This is the dominant slice, occupying the right half of the pie. It represents **58.8%** of outcomes, corresponding to **70** instances.
* **Correct (Light Green):** The second-largest slice, located on the left side. It accounts for **35.3%** of outcomes, or **42** instances.
* **Invalid JSON (Blue):** A small slice in the upper-left quadrant. It represents **2.5%** of outcomes, or **3** instances.
* **Max Context Length Error (Orange):** A small slice adjacent to the Invalid JSON slice. It also represents **2.5%** of outcomes, or **3** instances.
* **Max Actions Error (Yellow):** The smallest slice, a thin wedge next to the orange slice. It represents **0.8%** of outcomes, or **1** instance.
* **Total Count (GPT-4o):** 70 + 42 + 3 + 3 + 1 = **119** total trials.
#### **Chart 2: Errors Claude Opus (Right)**
* **Invalid JSON (Blue):** This is the largest slice, occupying the top-right quadrant. It represents **42.9%** of outcomes, corresponding to **51** instances.
* **Wrong (Red):** The second-largest slice, located in the bottom-right quadrant. It accounts for **27.7%** of outcomes, or **33** instances.
* **Correct (Light Green):** The third-largest slice, on the left side. It represents **26.1%** of outcomes, or **31** instances.
* **Content Policy Error (Teal):** A small slice in the upper-left quadrant. It represents **3.4%** of outcomes, or **4** instances.
* **Total Count (Claude Opus):** 51 + 33 + 31 + 4 = **119** total trials.
### Key Observations
1. **Dominant Error Type Differs:** The primary failure mode for GPT-4o is providing a "Wrong" answer (58.8%). For Claude Opus, the primary failure is generating "Invalid JSON" (42.9%).
2. **Accuracy Comparison:** GPT-4o has a higher "Correct" rate (35.3% vs. 26.1%).
3. **Error Diversity:** GPT-4o exhibits a wider variety of error types (5 categories) compared to Claude Opus (4 categories). GPT-4o shows specific technical errors ("Max Context Length," "Max Actions") not seen in the Claude Opus chart.
4. **"Wrong" Answer Rate:** While "Wrong" is the top error for GPT-4o, it is the second-most common outcome for Claude Opus, at a significantly lower rate (27.7%).
5. **Total Trials:** Both models were evaluated on the same number of trials (119), allowing for direct comparison of counts.
### Interpretation
This data suggests a fundamental difference in the failure profiles of the two models on this specific task. GPT-4o is more likely to produce a semantically incorrect but structurally valid response ("Wrong"). In contrast, Claude Opus struggles more with structural output formatting, as evidenced by its high rate of "Invalid JSON" errors.
The presence of "Max Context Length" and "Max Actions" errors exclusively for GPT-4o may indicate it is more prone to hitting operational limits during this task. Conversely, Claude Opus encounters "Content Policy" errors, a category not observed for GPT-4o in this dataset.
Despite GPT-4o's higher accuracy, its error distribution is more skewed towards a single, dominant category ("Wrong"). Claude Opus's errors are more evenly distributed between structural ("Invalid JSON") and semantic ("Wrong") issues. This analysis implies that debugging efforts for each model would need to target different root causes: improving answer correctness for GPT-4o versus improving output formatting and adherence to structural constraints for Claude Opus.