## Pie Charts: Model Error Analysis
### Overview
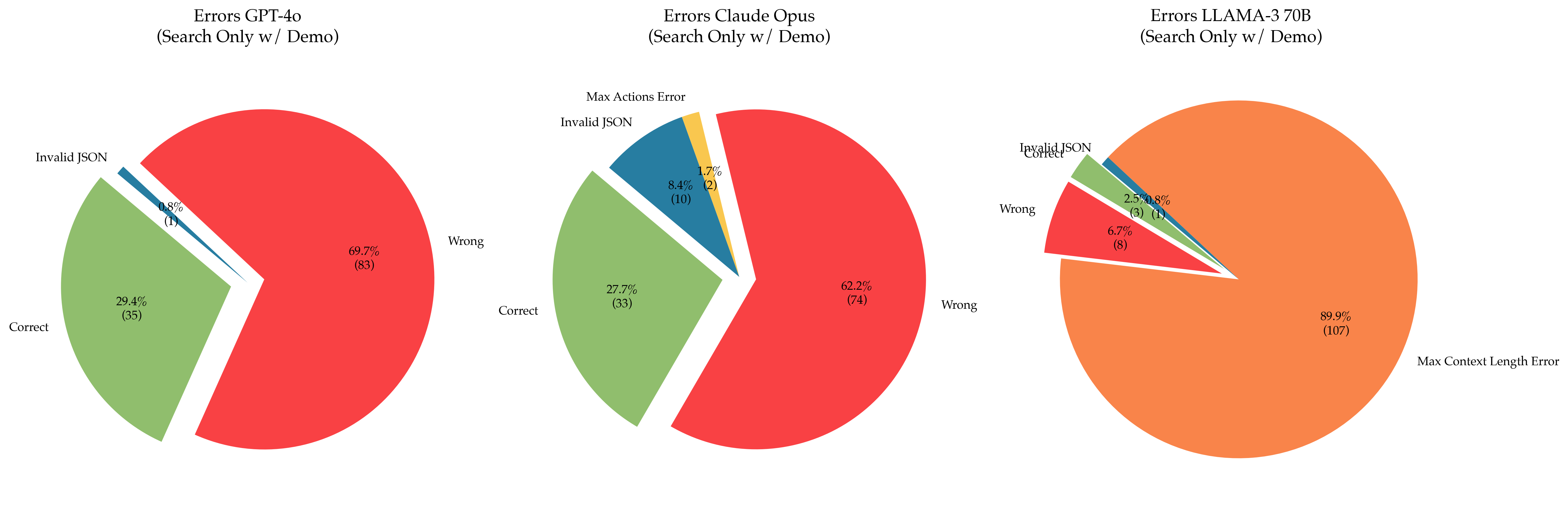
The image presents three pie charts, each depicting the error distribution for a different language model: GPT-4o, Claude Opus, and LLAMA-3 70B. The charts show the percentage and count of "Correct" responses, "Wrong" responses, "Invalid JSON" errors, and "Max Actions Error" (for Claude Opus) and "Max Context Length Error" (for LLAMA-3 70B) when using a "Search Only w/ Demo" configuration.
### Components/Axes
Each pie chart represents a model's error distribution. The slices are labeled with the error type and display both the percentage and the absolute count in parentheses.
* **GPT-4o:**
* Title: Errors GPT-4o (Search Only w/ Demo)
* Categories: Correct, Wrong, Invalid JSON
* **Claude Opus:**
* Title: Errors Claude Opus (Search Only w/ Demo)
* Categories: Correct, Wrong, Invalid JSON, Max Actions Error
* **LLAMA-3 70B:**
* Title: Errors LLAMA-3 70B (Search Only w/ Demo)
* Categories: Correct, Wrong, Invalid JSON, Max Context Length Error
### Detailed Analysis or ### Content Details
**GPT-4o:**
* **Correct:** 29.4% (35) - Light Green
* **Wrong:** 69.7% (83) - Red
* **Invalid JSON:** 0.8% (1) - Dark Blue
**Claude Opus:**
* **Correct:** 27.7% (33) - Light Green
* **Wrong:** 62.2% (74) - Red
* **Invalid JSON:** 8.4% (10) - Dark Blue
* **Max Actions Error:** 1.7% (2) - Yellow
**LLAMA-3 70B:**
* **Correct:** 2.5% (3) - Light Green
* **Wrong:** 6.7% (8) - Red
* **Invalid JSON:** 0.8% (1) - Dark Blue
* **Max Context Length Error:** 89.9% (107) - Orange
### Key Observations
* GPT-4o has a high percentage of "Wrong" responses (69.7%).
* Claude Opus has a more balanced distribution, with a significant percentage of "Wrong" (62.2%) and "Correct" (27.7%) responses, along with some "Invalid JSON" errors (8.4%) and "Max Actions Error" (1.7%).
* LLAMA-3 70B is dominated by "Max Context Length Error" (89.9%), with very few "Correct" or "Wrong" responses.
### Interpretation
The pie charts provide a comparative analysis of the error profiles of three different language models under the same "Search Only w/ Demo" conditions. The data suggests that:
* GPT-4o struggles with providing correct answers, as indicated by the high percentage of "Wrong" responses.
* Claude Opus exhibits a more diverse error profile, suggesting potential issues with both correctness and adherence to constraints (Max Actions).
* LLAMA-3 70B is severely limited by its context length, leading to a very high percentage of "Max Context Length Error". This indicates that the model is frequently unable to process the input within its context window.
The "Search Only w/ Demo" configuration likely imposes specific constraints or limitations that affect each model differently. The high error rates, particularly for LLAMA-3 70B, suggest that this configuration may not be optimal for all models.