## Pie Charts: Error Analysis of Large Language Models
### Overview
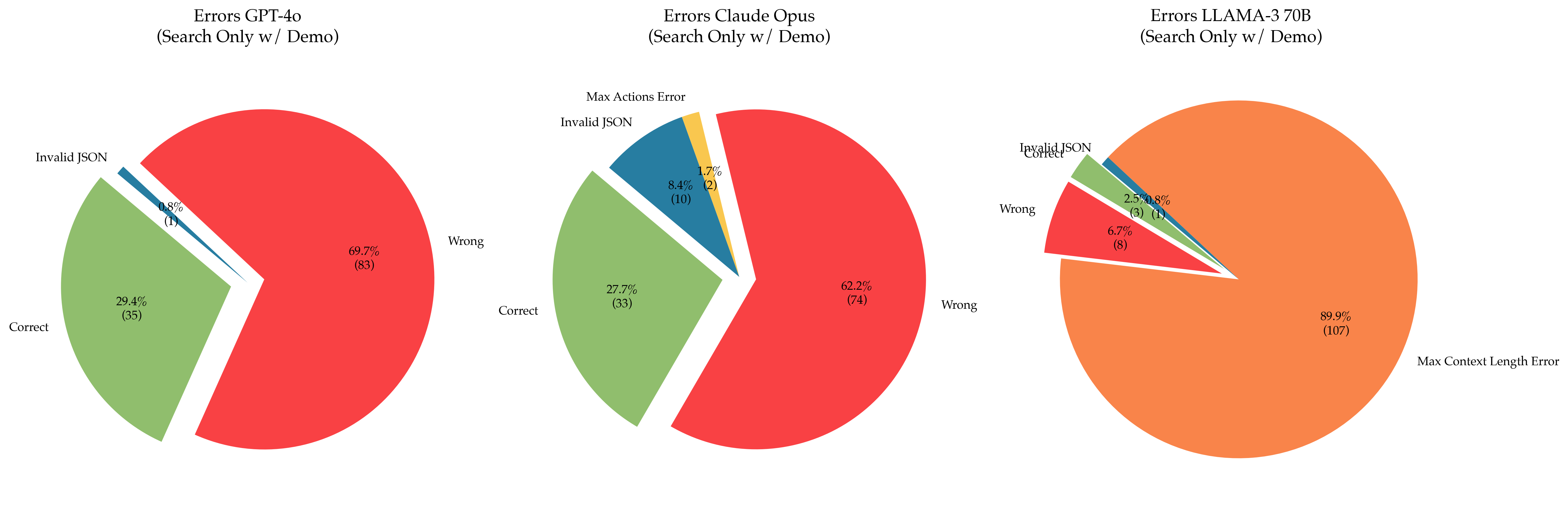
The image presents three pie charts, each representing the error distribution for a different Large Language Model (LLM): GPT-4o, Claude Opus, and Llama-3 70B. All models were evaluated using a "Search Only w/ Demo" methodology. Each pie chart categorizes errors into "Correct", "Wrong", "Invalid JSON", and "Max Actions Error" (or "Max Context Length Error" for Llama-3). The charts also display the percentage and count of each error type.
### Components/Axes
Each chart has the following components:
* **Title:** Indicates the LLM being analyzed and the evaluation methodology.
* **Pie Slices:** Represent the proportion of each error category.
* **Labels:** Each slice is labeled with the error category and its percentage and count (in parentheses).
* **Color Coding:** Each error category is assigned a distinct color.
### Detailed Analysis or Content Details
**GPT-4o (Search Only w/ Demo)**
* **Correct:** 29.4% (35) - Represented by a green slice.
* **Wrong:** 69.7% (83) - Represented by a red slice.
* **Invalid JSON:** 0.9% (1) - Represented by a blue slice.
**Claude Opus (Search Only w/ Demo)**
* **Correct:** 27.7% (33) - Represented by a green slice.
* **Wrong:** 62.2% (74) - Represented by a red slice.
* **Invalid JSON:** 8.4% (10) - Represented by a blue slice.
* **Max Actions Error:** 1.7% (2) - Represented by an orange slice.
**Llama-3 70B (Search Only w/ Demo)**
* **Wrong:** 6.7% (8) - Represented by a red slice.
* **Invalid JSON:** 2.5% (3) - Represented by a blue slice.
* **Max Context Length Error:** 89.9% (107) - Represented by an orange slice.
* **Correct:** Not explicitly shown, but implied to be the remaining percentage.
### Key Observations
* GPT-4o and Claude Opus have a significant proportion of "Wrong" answers, around 70% and 62% respectively.
* Llama-3 70B exhibits a drastically different error profile, with the overwhelming majority of errors being "Max Context Length Error" (almost 90%).
* Invalid JSON errors are relatively low for all models, except for Claude Opus, which has 8.4%.
* GPT-4o has the lowest percentage of correct answers (29.4%) among the three models.
* Claude Opus has the highest percentage of correct answers (27.7%) among the three models.
### Interpretation
The data suggests that GPT-4o and Claude Opus struggle with providing accurate responses ("Wrong" errors) when using the "Search Only w/ Demo" methodology. The high percentage of "Wrong" answers indicates a potential issue with the models' ability to effectively utilize search results or generate correct outputs based on the provided context. The relatively low "Invalid JSON" error rate suggests that the models are generally capable of producing valid JSON output when required.
Llama-3 70B, however, presents a different challenge. The dominant "Max Context Length Error" suggests that the model is frequently exceeding its context window during the search and demo process. This could be due to the complexity of the search queries, the length of the demo content, or limitations in the model's context handling capabilities. The low "Wrong" error rate suggests that when Llama-3 *can* process the information within its context window, it tends to generate more accurate responses.
The differences in error profiles highlight the unique strengths and weaknesses of each model. GPT-4o and Claude Opus appear to be more prone to factual inaccuracies, while Llama-3 70B is limited by its context window. The "Search Only w/ Demo" methodology may be particularly challenging for Llama-3 70B, potentially requiring strategies to reduce the amount of information processed within a single context window.