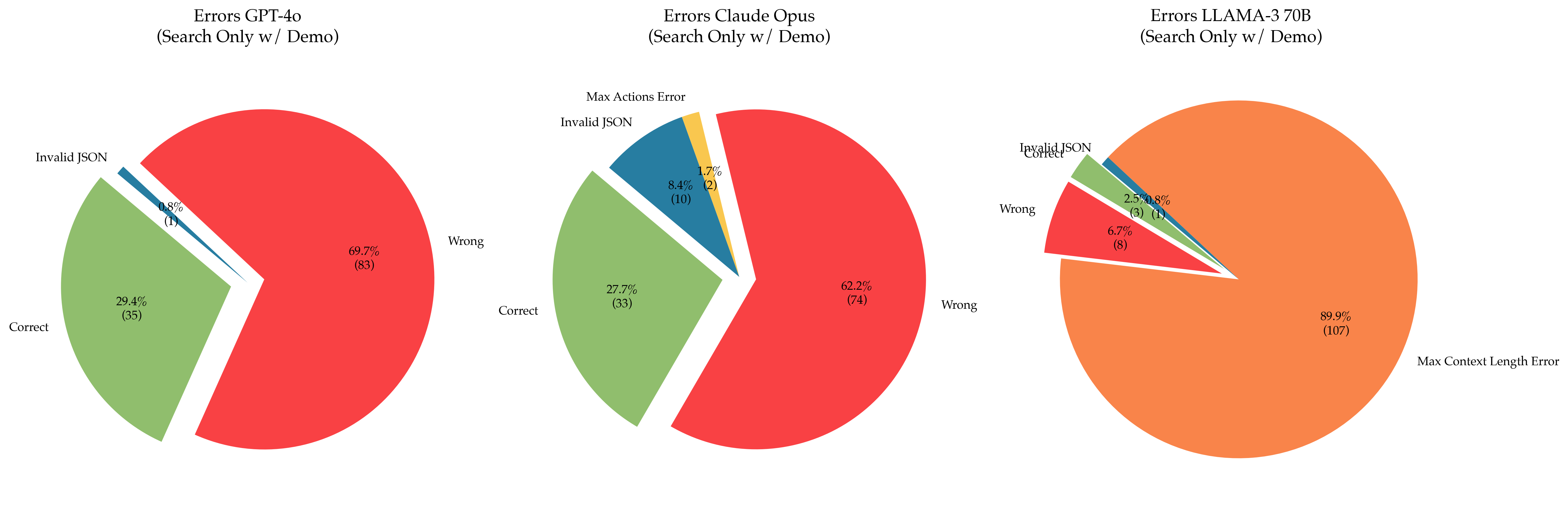
## [Pie Charts]: Error Distribution Comparison for Three AI Models in a "Search Only w/ Demo" Task
### Overview
The image displays three pie charts arranged horizontally, each illustrating the distribution of outcomes (errors and correct responses) for a different large language model (LLM) performing a "Search Only w/ Demo" task. The charts compare GPT-4o, Claude Opus, and LLAMA-3 70B. The primary insight is the stark difference in the dominant failure mode for the LLAMA-3 70B model compared to the other two.
### Components/Axes
* **Chart Titles (Top Center of each chart):**
* Left: `Errors GPT-4o (Search Only w/ Demo)`
* Center: `Errors Claude Opus (Search Only w/ Demo)`
* Right: `Errors LLAMA-3 70B (Search Only w/ Demo)`
* **Chart Type:** Pie charts (exploded slices for emphasis).
* **Data Categories (Legend/Labels):** The categories are labeled directly on or adjacent to their respective pie slices. The consistent color coding across charts is:
* **Red:** `Wrong`
* **Green:** `Correct`
* **Blue:** `Invalid JSON`
* **Yellow:** `Max Actions Error` (Only present in the Claude Opus chart)
* **Orange:** `Max Context Length Error` (Only present in the LLAMA-3 70B chart)
* **Data Format:** Each slice is labeled with a percentage and, in parentheses, the absolute count of instances for that category.
### Detailed Analysis
**1. GPT-4o (Left Chart)**
* **Wrong (Red):** The largest slice, positioned on the right side of the pie. **69.7% (83 instances)**.
* **Correct (Green):** The second-largest slice, positioned on the left side. **29.4% (35 instances)**.
* **Invalid JSON (Blue):** A very thin slice between the Wrong and Correct slices. **0.8% (1 instance)**.
* **Total Instances:** 83 + 35 + 1 = 119.
**2. Claude Opus (Center Chart)**
* **Wrong (Red):** The largest slice, positioned on the right. **62.2% (74 instances)**.
* **Correct (Green):** The second-largest slice, positioned on the left. **27.7% (33 instances)**.
* **Invalid JSON (Blue):** A moderate slice between Correct and Wrong. **8.4% (10 instances)**.
* **Max Actions Error (Yellow):** A small slice adjacent to the Invalid JSON slice. **1.7% (2 instances)**.
* **Total Instances:** 74 + 33 + 10 + 2 = 119.
**3. LLAMA-3 70B (Right Chart)**
* **Max Context Length Error (Orange):** The overwhelmingly dominant slice, occupying almost the entire chart. **89.9% (107 instances)**.
* **Wrong (Red):** A small slice on the left side. **6.7% (8 instances)**.
* **Correct (Green):** A very small slice adjacent to the Wrong slice. **2.5% (3 instances)**.
* **Invalid JSON (Blue):** A very thin slice adjacent to the Correct slice. **0.8% (1 instance)**.
* **Total Instances:** 107 + 8 + 3 + 1 = 119.
### Key Observations
1. **Consistent Sample Size:** All three models were evaluated on the same number of instances (119), allowing for direct comparison.
2. **Dominant Failure Modes Differ:**
* For **GPT-4o** and **Claude Opus**, the primary failure is providing a `Wrong` answer (69.7% and 62.2% respectively).
* For **LLAMA-3 70B**, the primary failure is a technical `Max Context Length Error` (89.9%), which is a different category of failure altogether.
3. **Correctness Rate:** GPT-4o (29.4%) and Claude Opus (27.7%) have similar, modest correctness rates. LLAMA-3 70B's correctness rate is drastically lower (2.5%).
4. **Error Diversity:** Claude Opus exhibits the widest variety of error types (4 categories), including the unique `Max Actions Error`. GPT-4o shows only two error types, while LLAMA-3 70B's errors are almost entirely of one type.
5. **Invalid JSON:** This error is present in all models but is most frequent in Claude Opus (8.4%).
### Interpretation
This data suggests a fundamental difference in how these models handle the "Search Only w/ Demo" task, likely related to their architecture, context window management, or training.
* **GPT-4o and Claude Opus** appear to be operating within their technical limits (rarely hitting action or context limits) but struggle with the *substantive correctness* of their outputs. Their performance is limited by reasoning or knowledge accuracy.
* **LLAMA-3 70B**, however, is failing for a *procedural/technical* reason before it can even attempt the task correctly. The `Max Context Length Error` indicates the model's input or generated output exceeded its maximum allowed context window. This suggests the task's demonstrations or search results are too lengthy for this model's configuration, making it an unsuitable choice for this specific workflow without modification (e.g., chunking, summarization).
* The comparison highlights that model evaluation must consider both **substantive accuracy** (Wrong vs. Correct) and **operational reliability** (technical errors like context length). A model might be conceptually capable but practically unusable for a given task due to technical constraints. The choice of model for this "Search Only w/ Demo" task would depend on whether the priority is minimizing wrong answers (favoring GPT-4o/Claude Opus) or ensuring the task runs to completion without technical failure (which none do perfectly, but LLAMA-3 70B fails at this spectacularly).