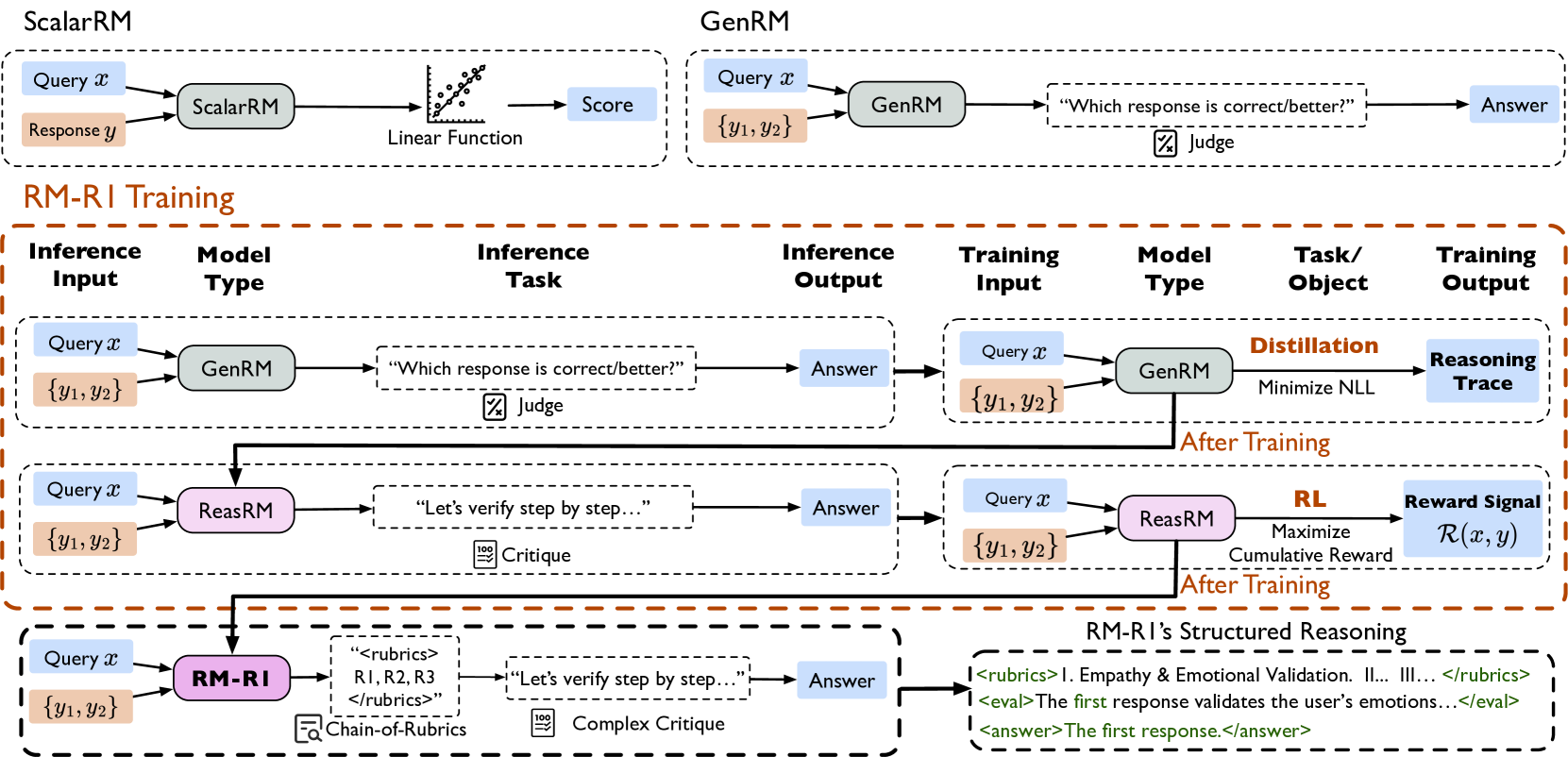
## Flowchart: Reasoning Model Architecture and Training Pipeline
### Overview
The image depicts a multi-stage reasoning model architecture with three primary components:
1. **ScalarRM** (Scalar Reasoning Model)
2. **GenRM** (Generative Reasoning Model)
3. **RM-RI** (Reasoning Model with Reinforcement Inference)
The diagram illustrates model types, inference tasks, training processes, and structured reasoning workflows, emphasizing iterative improvement through feedback loops and validation criteria.
---
### Components/Axes
#### Labels and Color Coding:
- **Blue**: Query (`x`)
- **Orange**: Response (`y`, `{y₁, y₂}`)
- **Gray**: Model Type (ScalarRM, GenRM, ReasRM, RM-RI)
- **Pink**: ReasRM (Reasoning Model)
- **Purple**: RM-RI (Reasoning Model with Reinforcement Inference)
- **Green**: Structured Reasoning Rubrics/Evaluation
#### Key Elements:
1. **ScalarRM**
- Input: Query (`x`) + Response (`y`)
- Process: Linear Function → Score
- Output: Score (quantitative evaluation)
2. **GenRM**
- Input: Query (`x`)
- Process: Generates multiple responses (`{y₁, y₂}`)
- Task: "Which response is correct/better?"
- Output: Selected Answer via Judge
3. **RM-RI Training**
- **Inference Input**: Query (`x`) + Response (`{y₁, y₂}`)
- **Model Type**: GenRM/ReasRM
- **Inference Task**:
- GenRM: Response selection via Judge
- ReasRM: Step-by-step verification via Critique
- **Training Input**: Query (`x`) + Response (`{y₁, y₂}`)
- **Model Type**: GenRM/ReasRM
- **Task/Object**:
- GenRM: Distillation (Minimize NLL)
- ReasRM: Reward Learning (Maximize `R(x,y)`)
- **Training Output**:
- GenRM: Reasoning Trace
- ReasRM: Reward Signal
4. **RM-RI's Structured Reasoning**
- Input: Query (`x`) + Response (`{y₁, y₂}`)
- Process: Chain-of-Rubrics with Complex Critique
- Output: Answer validated via:
- Empathy & Emotional Validation
- Step-by-Step Logical Consistency
---
### Detailed Analysis
#### ScalarRM vs. GenRM
- **ScalarRM** focuses on quantitative scoring via linear functions, suitable for simple tasks.
- **GenRM** handles generative tasks, producing multiple responses and using a "Judge" to select optimal answers.
#### RM-RI Training Pipeline
1. **Distillation Phase** (GenRM):
- Minimizes Negative Log Likelihood (NLL) to refine response generation.
- Outputs a "Reasoning Trace" for transparency.
2. **Reward Learning Phase** (ReasRM):
- Maximizes cumulative reward `R(x,y)` using reinforcement learning (RL).
- Emphasizes step-by-step verification via Critique.
#### RM-RI's Structured Reasoning
- Integrates **Chain-of-Rubrics** for multi-criteria evaluation:
- **Rubric I**: Empathy & Emotional Validation
- **Rubric II**: Logical Consistency
- **Rubric III**: Contextual Relevance
- Validates responses through iterative critiques and emotional grounding.
---
### Key Observations
1. **Hierarchical Complexity**:
- Progression from basic scoring (ScalarRM) to generative reasoning (GenRM) to structured, reward-driven reasoning (RM-RI).
2. **Feedback Loops**:
- "Judge" and "Critique" components enable iterative refinement of responses.
3. **Validation Framework**:
- RM-RI introduces **Chain-of-Rubrics** to enforce multi-dimensional evaluation (e.g., emotional validation, logical consistency).
4. **Training Objectives**:
- GenRM prioritizes accuracy (minimize NLL), while ReasRM focuses on robustness (maximize reward).
---
### Interpretation
The diagram represents a **multi-modal reasoning framework** designed to address limitations in traditional models:
- **ScalarRM** provides foundational scoring but lacks generative capability.
- **GenRM** improves response diversity but risks incoherence without validation.
- **RM-RI** bridges these gaps by combining generative power with structured reasoning and reinforcement learning.
**Notable Innovations**:
- **Chain-of-Rubrics**: Explicitly encodes evaluation criteria (e.g., empathy, logic) into the model's reasoning process.
- **Reward Signal**: Aligns training with human-like validation metrics, moving beyond raw accuracy.
**Implications**:
- The architecture suggests a shift toward **context-aware AI systems** capable of balancing factual correctness with emotional and logical coherence.
- The use of "Critique" and "Judge" components highlights the importance of **self-correction mechanisms** in advanced reasoning models.