## Diagram: Multi-Agent Reinforcement Learning Architecture
### Overview
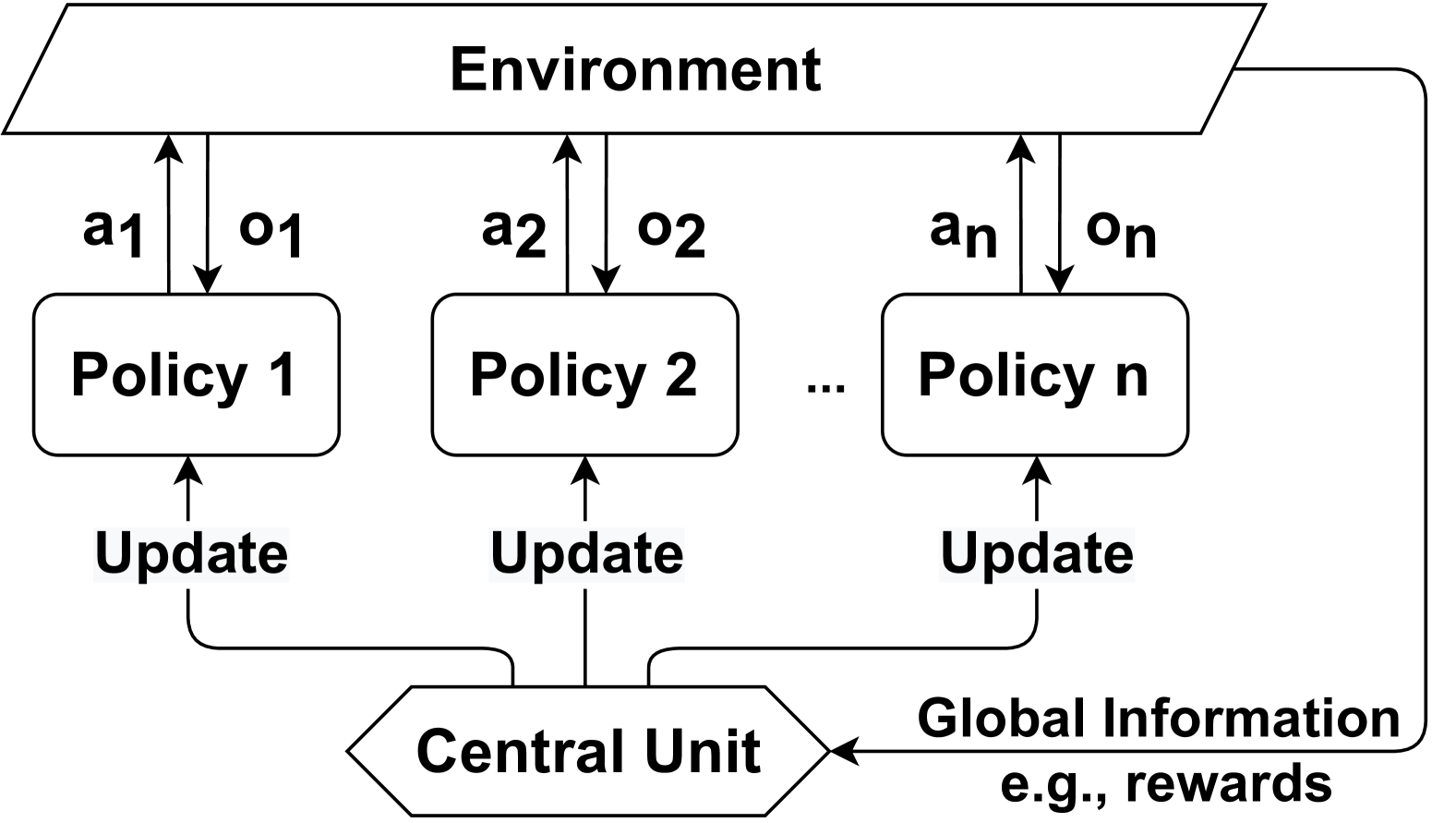
The image depicts a multi-agent reinforcement learning architecture. It shows an environment interacting with multiple policies (Policy 1, Policy 2, ..., Policy n), each receiving observations and taking actions. A central unit provides global information, such as rewards, to update these policies.
### Components/Axes
* **Environment:** Represented by a trapezoidal shape at the top.
* **Policies:** Represented by rounded rectangles labeled "Policy 1", "Policy 2", and "Policy n".
* **Central Unit:** Represented by a diamond shape at the bottom.
* **Actions:** Represented by upward arrows labeled "a1", "a2", and "an" from each policy to the environment.
* **Observations:** Represented by downward arrows labeled "o1", "o2", and "on" from the environment to each policy.
* **Updates:** Represented by upward arrows from the Central Unit to each policy.
* **Global Information:** Text label indicating the input to the Central Unit, with an example "e.g., rewards".
### Detailed Analysis or ### Content Details
* **Environment:** The environment interacts with each policy by sending observations (o1, o2, ..., on) and receiving actions (a1, a2, ..., an).
* **Policies:** Each policy (Policy 1, Policy 2, ..., Policy n) receives observations from the environment and outputs actions.
* **Central Unit:** The central unit receives global information (e.g., rewards) and sends update signals to each policy.
* **Flow:** The flow of information is as follows:
1. Environment -> Observations (o1, o2, ..., on) -> Policies
2. Policies -> Actions (a1, a2, ..., an) -> Environment
3. Central Unit -> Updates -> Policies
4. Environment -> Global Information (e.g., rewards) -> Central Unit
### Key Observations
* The diagram illustrates a distributed reinforcement learning setup where multiple agents (policies) interact with a shared environment.
* A central unit coordinates the learning process by providing global information to update the individual policies.
* The "..." between Policy 2 and Policy n indicates that there can be an arbitrary number of policies.
### Interpretation
The diagram represents a common architecture for multi-agent reinforcement learning. Each agent (policy) learns to interact with the environment based on its own observations and the global information provided by the central unit. The central unit likely aggregates information from the environment to provide a global reward signal or other relevant information to guide the learning process of each policy. This architecture allows for distributed learning and can be applied to various scenarios where multiple agents need to coordinate or compete in a shared environment. The global information provided by the central unit is crucial for coordinating the agents and ensuring that they learn to achieve a common goal.