\n
## Diagram: Multi-Policy Learning System
### Overview
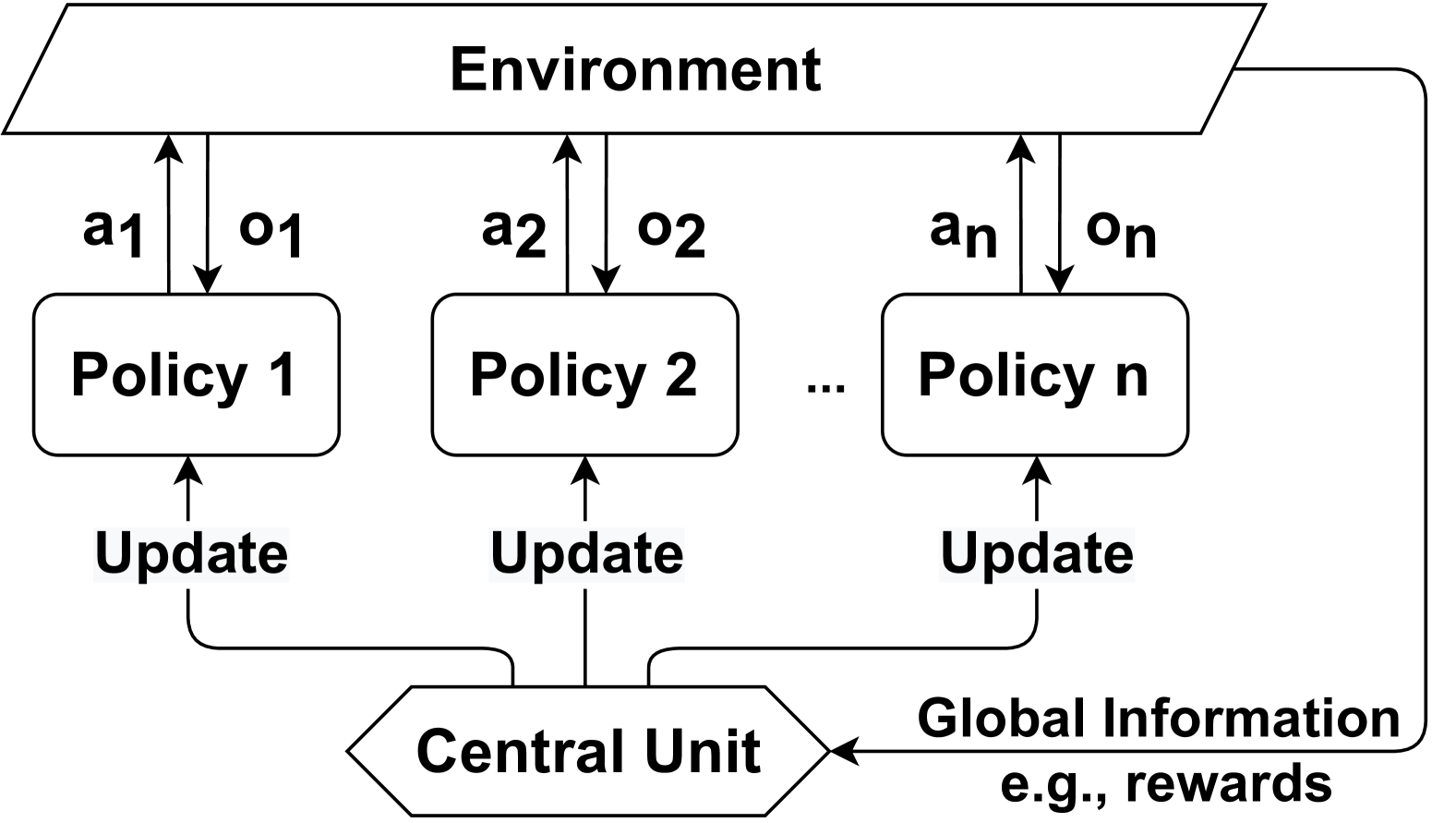
The image depicts a diagram of a multi-policy learning system within an environment. It illustrates how multiple policies interact with the environment and a central unit for updates and global information sharing. The diagram uses rounded rectangles to represent policies and a larger rectangle to represent the environment. Arrows indicate the flow of information and updates.
### Components/Axes
The diagram consists of the following components:
* **Environment:** A large, light-grey rectangle encompassing all policies. Labeled "Environment" at the top-center.
* **Policies:** Multiple rounded rectangles labeled "Policy 1", "Policy 2", and "Policy n" (with "..." indicating more policies exist).
* **Actions:** Arrows labeled "a1", "a2", and "an" pointing from the Environment to each respective Policy.
* **Observations:** Arrows labeled "o1", "o2", and "on" pointing from each Policy to the Environment.
* **Update:** Curved arrows labeled "Update" pointing from each Policy to the "Central Unit".
* **Central Unit:** A rounded rectangle labeled "Central Unit" at the bottom-center.
* **Global Information:** An arrow labeled "Global Information e.g., rewards" pointing from the Central Unit to the Environment.
### Detailed Analysis or Content Details
The diagram shows a system with 'n' number of policies interacting with an environment. Each policy receives an action 'a' from the environment and produces an observation 'o' which is sent back to the environment. Each policy is updated based on information from a central unit. The central unit receives updates from all policies and provides global information (such as rewards) back to the environment.
Specifically:
* Policy 1 receives action 'a1' and sends observation 'o1'.
* Policy 2 receives action 'a2' and sends observation 'o2'.
* Policy n receives action 'an' and sends observation 'on'.
* The "Update" signal flows from each Policy (1 to n) to the "Central Unit".
* The "Global Information" signal flows from the "Central Unit" to the "Environment".
### Key Observations
The diagram highlights a distributed learning architecture where multiple policies learn concurrently within the same environment. The central unit acts as a coordinator, aggregating information from all policies and distributing global information. The use of 'n' suggests scalability and the ability to handle a variable number of policies.
### Interpretation
This diagram likely represents a reinforcement learning system employing a multi-agent approach. The environment provides actions to each policy, and the policies learn to optimize their behavior based on the observations they receive. The central unit could be implementing a form of centralized training or experience replay, where information from all policies is used to improve the overall learning process. The "Global Information" (e.g., rewards) suggests a shared reward structure, where all policies are working towards a common goal. The system could be used for complex tasks where a single policy is insufficient, or where parallel learning can accelerate the training process. The diagram emphasizes the interplay between individual policy learning and centralized coordination.