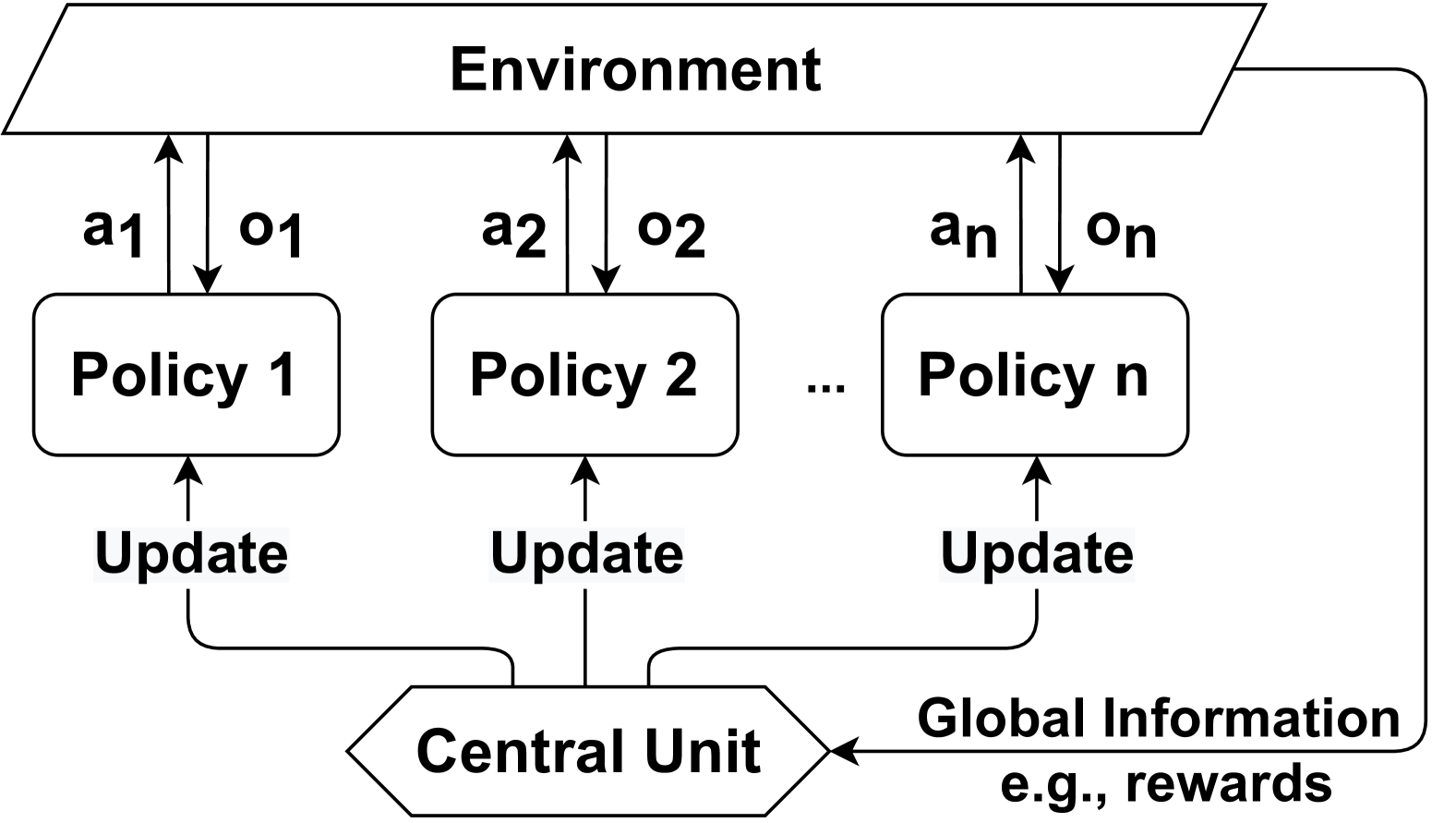
## Flowchart: Decentralized Policy-Environment Interaction System
### Overview
The diagram illustrates a decentralized system where multiple policies interact with an environment through a central coordination unit. Each policy receives environmental observations, generates actions, and sends updates to a central unit, which then provides global information (e.g., rewards) back to the environment.
### Components/Axes
1. **Environment**: Topmost rectangular box labeled "Environment"
2. **Policies**:
- Three labeled policy boxes: "Policy 1", "Policy 2", ..., "Policy n"
- Each policy has:
- Action arrow labeled "a1", "a2", ..., "an" (upward to environment)
- Observation arrow labeled "o1", "o2", ..., "on" (downward from environment)
- Update arrow labeled "Update" (downward to central unit)
3. **Central Unit**: Diamond-shaped box labeled "Central Unit" at bottom center
4. **Global Information**: Arrow from central unit to environment labeled "Global Information e.g., rewards"
### Spatial Relationships
- Environment spans top of diagram
- Policies arranged horizontally below environment
- Central unit positioned at bottom center
- Arrows form closed loop: Environment → Policies → Central Unit → Environment
### Detailed Analysis
1. **Policy-Environment Interaction**:
- Each policy receives environmental observations (o1-on)
- Each policy sends actions (a1-an) to environment
- All policies send updates to central unit
2. **Central Unit Function**:
- Aggregates policy updates
- Generates global information (rewards)
- Distributes rewards back to environment
3. **System Flow**:
- Environment → Policies: Observations (o1-on)
- Policies → Environment: Actions (a1-an)
- Policies → Central Unit: Updates
- Central Unit → Environment: Global information
### Key Observations
1. Decentralized architecture with n policies operating in parallel
2. Bidirectional information flow between environment and policies
3. Central coordination for update aggregation and reward distribution
4. Scalable design (n policies can be added/removed)
### Interpretation
This diagram represents a multi-agent reinforcement learning system where:
- Policies learn independently through environmental interactions
- Central unit enables knowledge sharing through reward signals
- System maintains scalability while preserving policy autonomy
- The closed-loop structure suggests continuous learning and adaptation
The architecture balances decentralized decision-making with centralized coordination, typical of distributed machine learning systems where individual agents (policies) learn from local experiences while benefiting from global system feedback.