\n
## Bar Chart: E-CARE: Hedge Cue Distrib.
### Overview
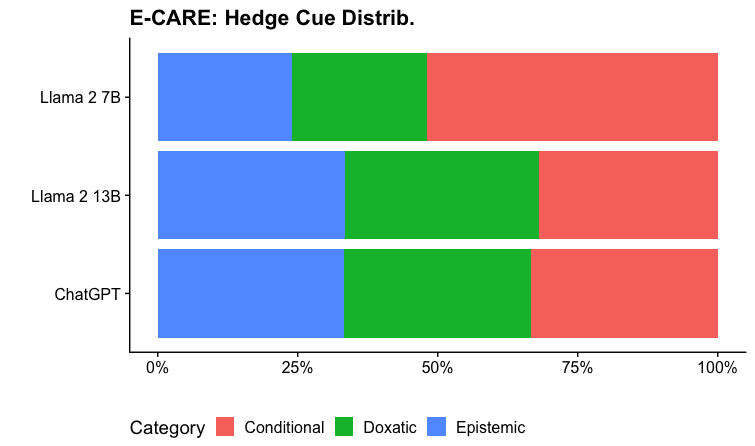
The image presents a horizontal bar chart comparing the distribution of three hedge cue categories – Conditional, Doxastic, and Epistemic – across three language models: Llama 2 7B, Llama 2 13B, and ChatGPT. Each bar represents 100% of the responses from a given model, segmented to show the proportion of each hedge cue category.
### Components/Axes
* **Title:** "E-CARE: Hedge Cue Distrib." positioned at the top-center.
* **Y-axis:** Lists the language models: "Llama 2 7B", "Llama 2 13B", and "ChatGPT" (from top to bottom).
* **X-axis:** Represents the percentage distribution, ranging from 0% to 100%.
* **Legend:** Located at the bottom-center, identifying the colors associated with each category:
* Conditional (Yellow)
* Doxastic (Green)
* Epistemic (Light Blue)
### Detailed Analysis
Each language model is represented by a horizontal bar, divided into three colored segments corresponding to the hedge cue categories.
* **Llama 2 7B:**
* Conditional (Yellow): Approximately 25%
* Doxastic (Green): Approximately 40%
* Epistemic (Light Blue): Approximately 35%
* **Llama 2 13B:**
* Conditional (Yellow): Approximately 20%
* Doxastic (Green): Approximately 50%
* Epistemic (Light Blue): Approximately 30%
* **ChatGPT:**
* Conditional (Yellow): Approximately 20%
* Doxastic (Green): Approximately 45%
* Epistemic (Light Blue): Approximately 35%
### Key Observations
* The Doxastic cue is the most prevalent across all three models, consistently occupying the largest segment of each bar.
* Llama 2 13B exhibits the highest proportion of Doxastic cues (approximately 50%).
* Llama 2 7B has the highest proportion of Conditional cues (approximately 25%).
* The Conditional cue consistently has the lowest proportion across all models.
### Interpretation
The chart suggests that all three language models, when responding within the E-CARE context, frequently employ Doxastic hedges – cues indicating belief or commitment. This could imply a tendency towards expressing opinions or making assertions, even while acknowledging uncertainty. The relatively lower use of Conditional hedges suggests a less frequent reliance on explicitly stating conditions or limitations. The differences between the models, particularly the higher Doxastic usage in Llama 2 13B and the higher Conditional usage in Llama 2 7B, might reflect variations in their training data or architectural design. These differences could be significant in applications where nuanced expression of uncertainty is crucial. The data suggests that the models are not equally calibrated in their use of hedging strategies. Further investigation would be needed to understand the implications of these differences for the reliability and trustworthiness of their outputs.