## Horizontal Stacked Bar Chart: E-CARE: Hedge Cue Distrib.
### Overview
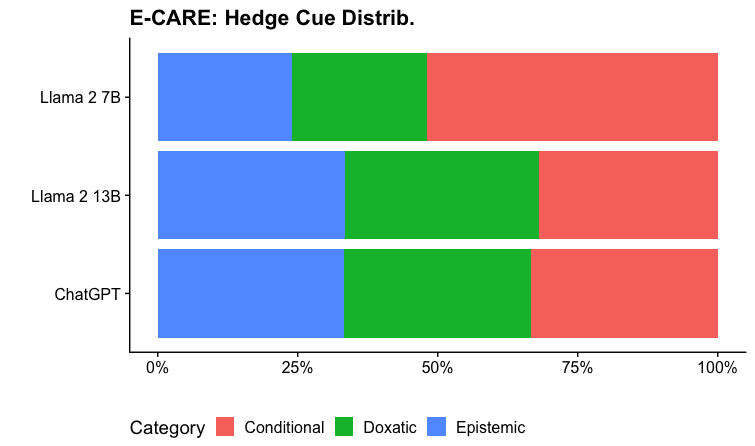
The image displays a horizontal stacked bar chart titled "E-CARE: Hedge Cue Distrib." It compares the distribution of three categories of "hedge cues" across three different large language models: Llama 2 7B, Llama 2 13B, and ChatGPT. The chart visualizes the proportional composition of each model's output in terms of these categories.
### Components/Axes
* **Chart Title:** "E-CARE: Hedge Cue Distrib." (located at the top center).
* **Y-Axis (Vertical):** Lists the three models being compared. From top to bottom: "Llama 2 7B", "Llama 2 13B", "ChatGPT".
* **X-Axis (Horizontal):** Represents a percentage scale from 0% to 100%. Major tick marks and labels are present at 0%, 25%, 50%, 75%, and 100%.
* **Legend:** Located at the bottom of the chart. It defines the color coding for the three categories:
* **Red Square:** "Conditional"
* **Green Square:** "Doxatic"
* **Blue Square:** "Epistemic"
* **Data Bars:** Three horizontal bars, one for each model. Each bar is segmented into three colored sections (blue, green, red) whose lengths represent the percentage share of each category.
### Detailed Analysis
The chart presents the following approximate percentage distributions for each model. Values are estimated based on the alignment of segment boundaries with the x-axis scale.
**1. Llama 2 7B (Top Bar):**
* **Epistemic (Blue, left segment):** Extends from 0% to approximately **25%**.
* **Doxatic (Green, middle segment):** Extends from ~25% to approximately **50%**. This segment represents about **25%** of the total.
* **Conditional (Red, right segment):** Extends from ~50% to 100%. This segment represents about **50%** of the total.
* **Trend:** The bar shows a clear majority of "Conditional" cues, with "Epistemic" and "Doxatic" cues making up roughly equal, smaller portions.
**2. Llama 2 13B (Middle Bar):**
* **Epistemic (Blue, left segment):** Extends from 0% to approximately **30%**.
* **Doxatic (Green, middle segment):** Extends from ~30% to approximately **65%**. This segment represents about **35%** of the total.
* **Conditional (Red, right segment):** Extends from ~65% to 100%. This segment represents about **35%** of the total.
* **Trend:** The distribution is more balanced than Llama 2 7B. "Doxatic" and "Conditional" cues are roughly equal in proportion, with "Epistemic" cues being the smallest category.
**3. ChatGPT (Bottom Bar):**
* **Epistemic (Blue, left segment):** Extends from 0% to approximately **30%**.
* **Doxatic (Green, middle segment):** Extends from ~30% to approximately **65%**. This segment represents about **35%** of the total.
* **Conditional (Red, right segment):** Extends from ~65% to 100%. This segment represents about **35%** of the total.
* **Trend:** The distribution for ChatGPT appears visually identical to that of Llama 2 13B.
### Key Observations
1. **Model Similarity:** Llama 2 13B and ChatGPT exhibit nearly identical distributions of hedge cue categories, suggesting similar behavior in this specific metric.
2. **Model Difference:** Llama 2 7B shows a distinctly different pattern, with a much higher proportion of "Conditional" cues (~50%) compared to the other two models (~35% each).
3. **Category Dominance:** For Llama 2 7B, "Conditional" is the dominant category. For Llama 2 13B and ChatGPT, no single category is overwhelmingly dominant, with "Doxatic" and "Conditional" being co-dominant.
4. **Epistemic Consistency:** The "Epistemic" category is the smallest segment for all three models, ranging from ~25% to ~30%.
### Interpretation
This chart from the E-CARE framework analyzes how different AI models use "hedge cues"—linguistic devices that express uncertainty or caution (e.g., "possibly," "it seems," "I think").
* **What the data suggests:** The distribution indicates a potential scaling effect or architectural difference between Llama 2 7B and its larger 13B counterpart. The 7B model relies more heavily on **Conditional** hedging (e.g., "If X, then Y"), which frames statements within specific conditions. The larger 13B model and ChatGPT shift towards a more balanced use of **Doxatic** hedging (related to belief or opinion, e.g., "I believe," "It is thought") alongside conditional statements.
* **Relationship between elements:** The near-identical profiles of Llama 2 13B and ChatGPT are striking. It could imply that at a certain scale or with sufficient training, models converge on a similar strategy for distributing uncertainty across these three linguistic categories. The outlier, Llama 2 7B, may represent a less nuanced or differently optimized approach to hedging.
* **Notable implication:** The type of hedging a model uses can affect the perceived reliability, tone, and safety of its outputs. A model heavy in conditional cues might sound more logically precise but also more restrictive, while one using more doxatic cues might sound more opinionated or subjective. This analysis provides a quantitative lens into the qualitative "voice" of different AI systems.