## Horizontal Bar Chart: E-CARE: Hedge Cue Distrib.
### Overview
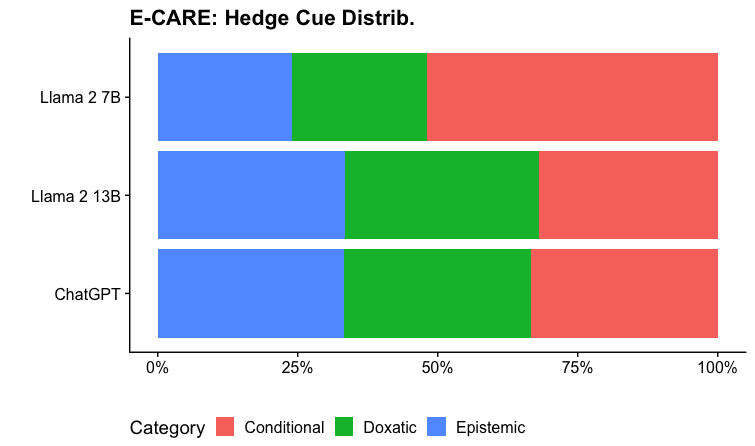
The chart compares the distribution of three hedge cue categories (Epistemic, Doxastic, Conditional) across three language models: Llama 2 7B, Llama 2 13B, and ChatGPT. Each model's bar is divided into color-coded segments representing the proportion of each cue type.
### Components/Axes
- **X-axis**: Labeled "Percentage" with markers at 0%, 25%, 50%, 75%, and 100%.
- **Y-axis**: Lists models (Llama 2 7B, Llama 2 13B, ChatGPT) from top to bottom.
- **Legend**: Located at the bottom, mapping colors to categories:
- **Blue**: Epistemic
- **Green**: Doxastic
- **Red**: Conditional
### Detailed Analysis
1. **Llama 2 7B**:
- **Epistemic (Blue)**: ~20% of the bar.
- **Doxastic (Green)**: ~30% of the bar.
- **Conditional (Red)**: ~50% of the bar (largest segment).
2. **Llama 2 13B**:
- **Epistemic (Blue)**: ~30% of the bar.
- **Doxastic (Green)**: ~40% of the bar.
- **Conditional (Red)**: ~30% of the bar (smallest segment among the three models).
3. **ChatGPT**:
- **Epistemic (Blue)**: ~30% of the bar.
- **Doxastic (Green)**: ~40% of the bar.
- **Conditional (Red)**: ~30% of the bar (matches Llama 2 13B's distribution).
### Key Observations
- **Conditional cues dominate** in all models, with Llama 2 7B having the highest proportion (~50%).
- **Llama 2 13B** shows the most balanced distribution, with Epistemic and Conditional cues nearly equal (~30% each).
- **ChatGPT** has the lowest Conditional proportion (~30%) but the highest Epistemic proportion (~30%) among the three models.
- All models allocate the largest segment to **Doxastic cues** (30–40%).
### Interpretation
The data suggests that **Conditional hedging** is a prevalent strategy across models, particularly in smaller architectures like Llama 2 7B. The **Llama 2 13B** model exhibits a more diversified cue distribution, potentially reflecting architectural complexity or training objectives. **ChatGPT**'s higher Epistemic proportion may indicate a design emphasis on uncertainty expression. The consistent dominance of Doxastic cues across models implies a shared focus on factual grounding, though the exact mechanisms differ by architecture.