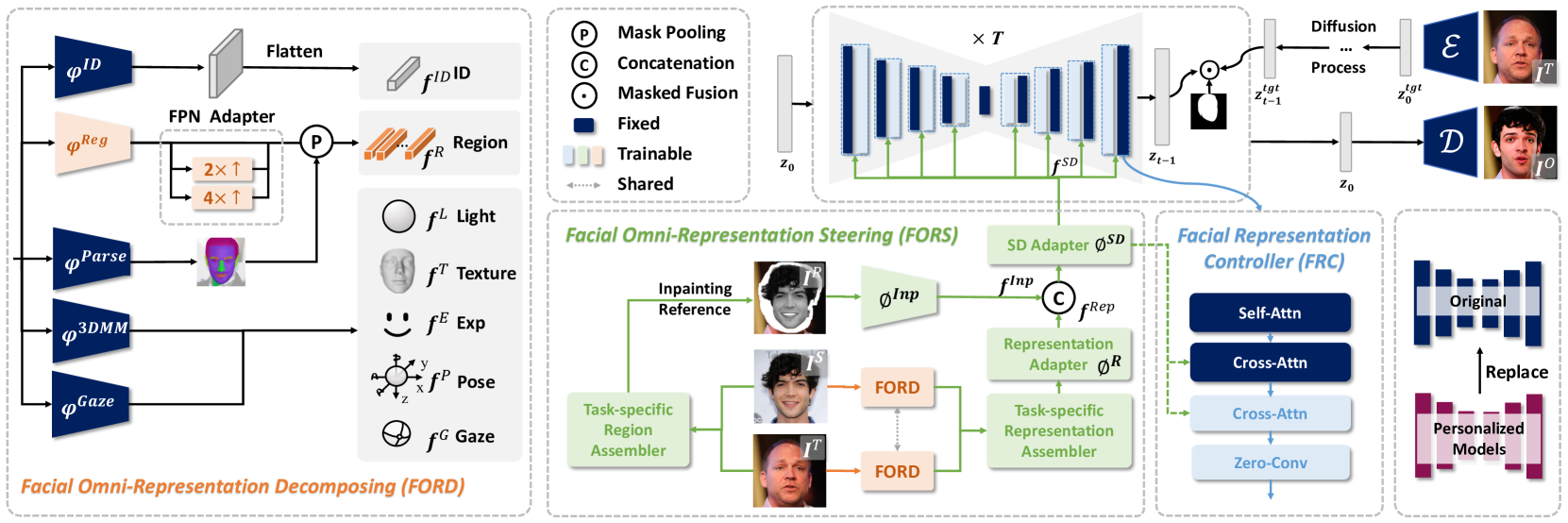
# Technical Document Extraction: Facial Omni-Representation Framework
## Overview
The image depicts a multi-stage computational framework for facial representation decomposition, steering, and control, integrated with a diffusion process. The system is divided into four primary components: **FORD** (Facial Omni-Representation Decomposing), **FORS** (Facial Omni-Representation Steering), **FRC** (Facial Representation Controller), and a **Diffusion Process**.
---
## 1. FORD (Facial Omni-Representation Decomposing)
### Components and Flow
- **Inputs**:
- `φ_ID`: Identity feature (blue box)
- `φ_Reg`: Region feature (orange box)
- `φ_Parse`: Parsing feature (gray box with face icon)
- `φ_3DMM`: 3D Morphable Model (dark blue box)
- `φ_Gaze`: Gaze direction (purple box)
- **Processing**:
- **Flatten**: Converts inputs into 1D vectors.
- **FPN Adapter**:
- 2× upsampling (dashed box)
- 4× upsampling (dashed box)
- **Mask Pooling**: Aggregates spatial information (symbol `P`).
- **Outputs**:
- `f_ID`: Identity feature map (gray bar)
- `f_Reg`: Region feature map (orange bar)
- `f_Parse`: Parsing feature map (gray bar with face icon)
- `f_3DMM`: 3DMM feature map (dark blue bar)
- `f_Gaze`: Gaze feature map (purple bar)
### Legend
- **Colors**:
- Blue: Fixed parameters
- Green: Trainable parameters
- Gray: Shared parameters
---
## 2. Diffusion Process
### Workflow
1. **Initialization**: Start with latent code `z₀`.
2. **Iterative Denoising**:
- **Mask Pooling**: Aggregates spatial features.
- **Concatenation**: Combines features across time steps.
- **Masked Fusion**: Applies attention masks (symbol `•`).
3. **Output**: Final denoised latent code `z_tgt` after `T` steps.
### Legend
- **Colors**:
- Blue: Fixed parameters
- Green: Trainable parameters
- Gray: Shared parameters
---
## 3. FORS (Facial Omni-Representation Steering)
### Components and Flow
- **Inputs**:
- **Inpainting Reference**: Source image (top-left face).
- **Task-specific Region Assembler**: Combines facial regions (middle-left).
- **Processing**:
- **FORD**: Integrates decomposed features.
- **SD Adapter** (`φ_SD`): Spatial denoising adapter (green box).
- **Representation Adapter** (`φ_Rep`): Task-specific adaptation (orange box).
- **Outputs**:
- `f_Inp`: Inpainting feature map (gray bar).
- `f_SD`: Spatial denoising feature map (green bar).
- `f_Rep`: Representation feature map (orange bar).
### Key Elements
- **Cross-Attention**: Links task-specific regions to global features.
- **Zero-Conv**: Simplifies feature integration (light blue box).
---
## 4. FRC (Facial Representation Controller)
### Components and Flow
- **Inputs**:
- **Original Model**: Baseline facial representation (left).
- **Processing**:
- **Self-Attention** (`Self-Attn`): Internal feature refinement (dark blue box).
- **Cross-Attention** (`Cross-Attn`): External feature integration (blue box).
- **Zero-Conv**: Lightweight feature transformation (light blue box).
- **Outputs**:
- **Personalized Models**: Customized facial representations (pink box).
### Legend
- **Colors**:
- Blue: Fixed parameters
- Green: Trainable parameters
- Gray: Shared parameters
---
## 5. Spatial Grounding and Color Consistency
- **Legend Placement**:
- Primary legend: Top-right corner (applies to FORD and Diffusion).
- Secondary legend: Bottom-right (applies to FRC).
- **Color Validation**:
- **FORD**: Blue (`φ_ID`), Orange (`φ_Reg`), Gray (`φ_Parse`), Dark Blue (`φ_3DMM`), Purple (`φ_Gaze`).
- **Diffusion**: Blue (Fixed), Green (Trainable), Gray (Shared).
- **FRC**: Blue (Fixed), Green (Trainable), Gray (Shared).
---
## 6. Key Trends and Data Points
- **FORD**: Decomposes facial features into identity, region, parsing, 3DMM, and gaze components.
- **Diffusion**: Iteratively denoises latent codes over `T` steps using masked fusion.
- **FORS**: Steers facial representations via task-specific inpainting and adaptation.
- **FRC**: Personalizes models using self-/cross-attention mechanisms.
---
## 7. Missing Data
- No numerical data tables or heatmaps present. All information is diagrammatic.
---
## 8. Final Notes
The framework integrates decomposition, steering, and control of facial representations, leveraging diffusion for high-quality image synthesis. Critical components include attention mechanisms, task-specific adapters, and iterative denoising.