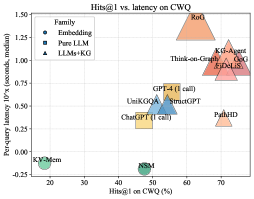
## Scatter Plot: Hits@1 vs. Latency on CWQ
### Overview
This scatter plot compares the performance of various models on the CWQ dataset, plotting **Hits@1 (accuracy)** against **latency (10^x seconds)**. Models are categorized into three families: **Embedding**, **Pure LLM**, and **LLMs+KG**, with distinct symbols and colors. The y-axis uses a logarithmic scale (10^x) to represent latency.
---
### Components/Axes
- **X-axis**: Hits@1 on CWQ (%)
- Range: 0–80%
- Labels: Discrete ticks at 20, 30, 40, 50, 60, 70.
- **Y-axis**: Per-query latency (10^x seconds, median)
- Range: -0.25 to 1.50 (log scale)
- Labels: Discrete ticks at -0.25, 0.0, 0.25, 0.5, 0.75, 1.0, 1.25, 1.50.
- **Legend**:
- **Embedding**: Green circles (●)
- **Pure LLM**: Blue squares (■)
- **LLMs+KG**: Orange triangles (▲)
---
### Detailed Analysis
#### Data Points and Trends
1. **Embedding (Green Circles)**:
- **KV-Mem**: (20%, -0.25)
- **NSM**: (50%, 0.0)
- **Trend**: Low Hits@1 and low latency.
2. **Pure LLM (Blue Squares)**:
- **ChatGPT (1 call)**: (50%, 0.5)
- **UniKGQA**: (45%, 0.5)
- **StructGPT**: (55%, 0.5)
- **GPT-4 (1 call)**: (60%, 0.75)
- **Trend**: Moderate Hits@1 (45–60%) with consistent latency (~0.5–0.75).
3. **LLMs+KG (Orange Triangles)**:
- **Think-On-Graph**: (65%, 1.0)
- **KG-Agent**: (70%, 1.25)
- **GoG**: (75%, 1.5)
- **FIDELIS**: (70%, 1.25)
- **RoG**: (75%, 1.5)
- **Trend**: High Hits@1 (65–75%) but significantly higher latency (1.0–1.5).
#### Spatial Grounding
- **Legend**: Top-left corner, clearly labeled with symbols and colors.
- **Data Points**:
- **Bottom-left**: Embedding models (KV-Mem, NSM).
- **Center**: Pure LLM models (ChatGPT, UniKGQA, StructGPT).
- **Top-right**: LLMs+KG models (Think-On-Graph, KG-Agent, GoG, FIDELIS, RoG).
---
### Key Observations
1. **Trade-off Between Accuracy and Latency**:
- LLMs+KG models dominate the top-right quadrant, achieving the highest Hits@1 but with the highest latency.
- Embedding models (KV-Mem, NSM) cluster in the bottom-left, showing poor performance in both metrics.
2. **Outliers**:
- **NSM**: (50%, 0.0) – Unusually low latency for its Hits@1 (50%), suggesting optimization or unique architecture.
- **KG-Agent** and **RoG**: Highest Hits@1 (70–75%) but extreme latency (1.25–1.5), indicating computational intensity.
3. **Logarithmic Scale Impact**:
- Latency values (10^x) amplify differences in the upper range (e.g., 1.5 vs. 1.0 = 10x increase).
---
### Interpretation
- **Performance Hierarchy**:
- **LLMs+KG** prioritize accuracy over speed, suitable for applications where precision is critical (e.g., medical diagnosis).
- **Pure LLMs** balance moderate accuracy and latency, ideal for general-purpose use.
- **Embedding models** are fast but less accurate, potentially useful for real-time systems with relaxed accuracy requirements.
- **Anomalies**:
- **NSM**’s low latency at 50% Hits@1 suggests it may use lightweight mechanisms (e.g., caching) or simplified queries.
- **KG-Agent** and **RoG**’s high latency could stem from complex knowledge graph traversal or large-scale inference.
- **Practical Implications**:
- Developers must weigh accuracy needs against computational costs. For example, GPT-4 (60% Hits@1, 0.75 latency) offers a middle ground, while RoG (75% Hits@1, 1.5 latency) is optimal for high-stakes scenarios.
- **Unanswered Questions**:
- Why do some LLMs+KG models (e.g., Think-On-Graph) achieve higher Hits@1 than others despite similar latency?
- How do query complexity or dataset characteristics influence these trade-offs?
---
### Conclusion
The chart highlights a clear Pareto frontier: no model dominates all others in both metrics. The choice of model depends on the application’s tolerance for latency versus the need for accuracy. Future work could explore hybrid approaches to mitigate the latency-accuracy trade-off.