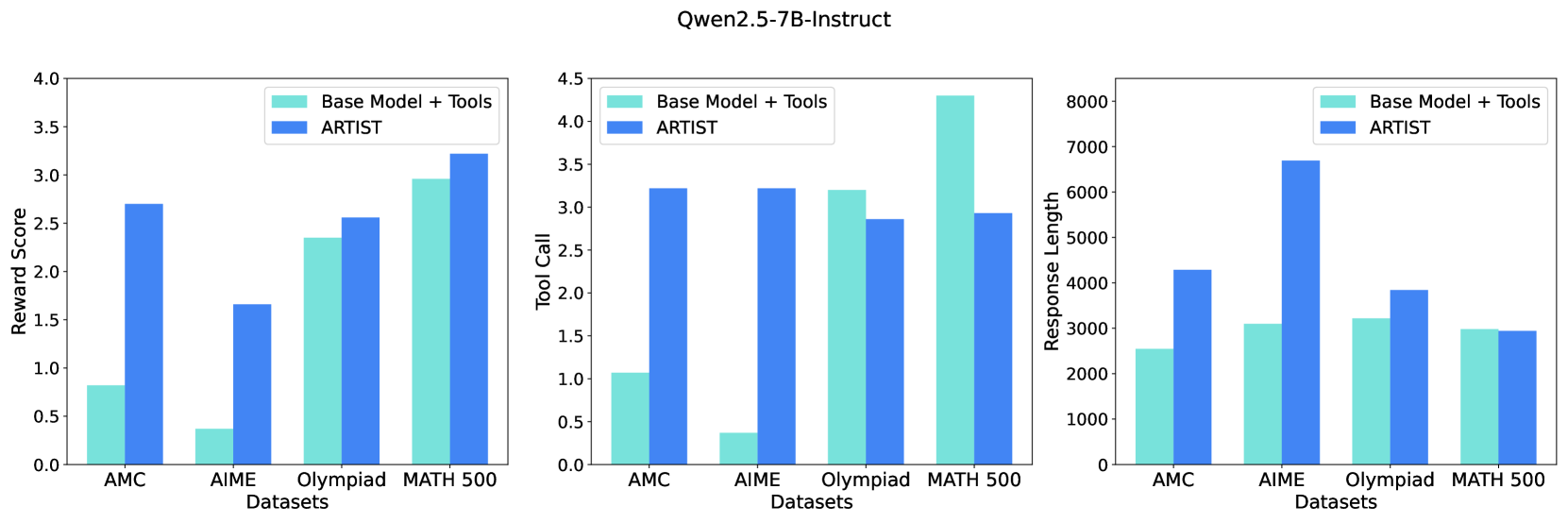
## Bar Chart: Qwen2.5-7B-Instruct Performance Comparison
### Overview
The image presents three bar charts comparing the performance of "Base Model + Tools" and "ARTIST" across four datasets: AMC, AIME, Olympiad, and MATH 500. Each chart visualizes a different metric: Reward Score, Tool Call, and Response Length. The charts are arranged horizontally, side-by-side.
### Components/Axes
Each chart shares the following components:
* **X-axis:** "Datasets" with categories: AMC, AIME, Olympiad, MATH 500.
* **Y-axis:** Varies per chart:
* Chart 1: "Reward Score" (Scale: 0.0 to 4.0)
* Chart 2: "Tool Call" (Scale: 0.0 to 4.5)
* Chart 3: "Response Length" (Scale: 0 to 8000)
* **Legend:** Located at the top-left of each chart, distinguishing between "Base Model + Tools" (light blue) and "ARTIST" (dark blue).
### Detailed Analysis or Content Details
**Chart 1: Reward Score**
* **AMC:** "Base Model + Tools" ≈ 2.6, "ARTIST" ≈ 0.7
* **AIME:** "Base Model + Tools" ≈ 2.1, "ARTIST" ≈ 1.7
* **Olympiad:** "Base Model + Tools" ≈ 2.7, "ARTIST" ≈ 2.3
* **MATH 500:** "Base Model + Tools" ≈ 3.2, "ARTIST" ≈ 3.1
The "Base Model + Tools" consistently achieves higher reward scores than "ARTIST" across all datasets. The difference is most pronounced for the AMC dataset.
**Chart 2: Tool Call**
* **AMC:** "Base Model + Tools" ≈ 3.1, "ARTIST" ≈ 3.0
* **AIME:** "Base Model + Tools" ≈ 3.2, "ARTIST" ≈ 3.1
* **Olympiad:** "Base Model + Tools" ≈ 3.5, "ARTIST" ≈ 3.3
* **MATH 500:** "Base Model + Tools" ≈ 4.0, "ARTIST" ≈ 3.8
"Base Model + Tools" generally exhibits a higher tool call rate than "ARTIST", with the largest difference observed in the MATH 500 dataset.
**Chart 3: Response Length**
* **AMC:** "Base Model + Tools" ≈ 3000, "ARTIST" ≈ 3000
* **AIME:** "Base Model + Tools" ≈ 3000, "ARTIST" ≈ 3000
* **Olympiad:** "Base Model + Tools" ≈ 6500, "ARTIST" ≈ 7000
* **MATH 500:** "Base Model + Tools" ≈ 4000, "ARTIST" ≈ 4000
The response length is similar for both models on AMC, AIME, and MATH 500. However, "ARTIST" generates significantly longer responses for the Olympiad dataset.
### Key Observations
* "Base Model + Tools" consistently outperforms "ARTIST" in Reward Score and Tool Call.
* Response Length is comparable for most datasets, except for Olympiad where "ARTIST" produces longer responses.
* The performance gap between the two models is most significant for the AMC dataset in terms of Reward Score.
### Interpretation
The data suggests that augmenting the base model with tools improves its performance, as measured by Reward Score and Tool Call, across various datasets. The longer response length of "ARTIST" on the Olympiad dataset might indicate a tendency to provide more verbose or detailed answers, potentially at the cost of conciseness or relevance (as reflected in the lower Reward Score). The consistent advantage of "Base Model + Tools" suggests that the tools are effectively utilized to enhance problem-solving capabilities. The relatively small difference in response length for AMC, AIME, and MATH 500 indicates that the tool integration doesn't drastically alter the length of the generated responses for those datasets. The data points to a trade-off between reward/tool usage and response length, with "ARTIST" favoring length and "Base Model + Tools" favoring efficiency and reward.