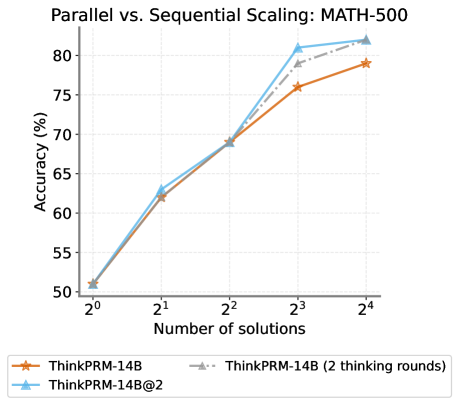
## Line Chart: Parallel vs. Sequential Scaling: MATH-500
### Overview
The chart compares the accuracy of three configurations of the ThinkPRM-14B model under parallel and sequential scaling for the MATH-500 benchmark. Accuracy is plotted against the number of solutions (2⁰ to 2⁴), with three data series representing different computational strategies.
### Components/Axes
- **X-axis**: "Number of solutions" (logarithmic scale: 2⁰, 2¹, 2², 2³, 2⁴).
- **Y-axis**: "Accuracy (%)" (linear scale: 50% to 80%, 5% increments).
- **Legend**: Located at the bottom, with three entries:
- **Orange**: ThinkPRM-14B (sequential scaling).
- **Gray dashed**: ThinkPRM-14B (2 thinking rounds, sequential).
- **Blue**: ThinkPRM-14B@2 (parallel scaling).
### Detailed Analysis
1. **ThinkPRM-14B (Orange)**:
- Starts at ~50.5% accuracy at 2⁰.
- Increases to ~62.5% at 2¹, ~69.5% at 2², ~76.5% at 2³, and ~78.5% at 2⁴.
- **Trend**: Gradual upward slope with diminishing returns at higher solution counts.
2. **ThinkPRM-14B (2 thinking rounds, Gray dashed)**:
- Starts at ~51% at 2⁰.
- Increases to ~63% at 2¹, ~70% at 2², ~78% at 2³, and ~82% at 2⁴.
- **Trend**: Steeper than the orange line, with consistent growth across all solution counts.
3. **ThinkPRM-14B@2 (Blue)**:
- Starts at ~50.5% at 2⁰.
- Increases to ~63.5% at 2¹, ~70% at 2², ~82% at 2³, and ~83% at 2⁴.
- **Trend**: Sharpest upward slope, outperforming other configurations at higher solution counts.
### Key Observations
- **Parallel scaling (blue line)** achieves the highest accuracy, particularly at 2³ and 2⁴ solutions.
- **Sequential scaling with 2 thinking rounds (gray dashed)** outperforms the base sequential model (orange) but lags behind parallel scaling.
- All configurations show diminishing returns as solution counts increase, but parallel scaling maintains a steeper growth trajectory.
### Interpretation
The data demonstrates that **parallel scaling (ThinkPRM-14B@2)** significantly enhances accuracy compared to sequential approaches, especially as the number of solutions grows. This suggests that parallel processing mitigates computational bottlenecks, enabling more efficient resource utilization. The two-thinking-rounds configuration (gray dashed) also improves performance over the base sequential model, but its gains are less pronounced than parallel scaling. The chart underscores the advantages of parallelization in scaling AI models for complex tasks like MATH-500, where computational efficiency directly impacts accuracy.
**Note**: Values are approximate due to the absence of gridlines or exact numerical labels on the chart.