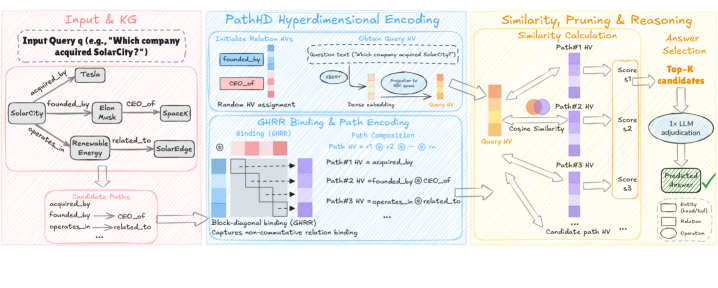
## Technical Diagram: PathHD Hyperdimensional Encoding Pipeline
### Overview
This image is a technical flowchart illustrating a system called "PathHD Hyperdimensional Encoding." The system processes a natural language query against a knowledge graph (KG) to find an answer by converting entities and relationships into hyperdimensional vectors (HVs), composing path representations, and performing similarity-based reasoning. The diagram is divided into three main processing stages, flowing from left to right.
### Components/Axes
The diagram is segmented into three primary colored regions, each representing a major processing stage:
1. **Input & KG (Left, Pink Border):**
* **Input Query:** "Input Query (e.g., 'Which company acquired SolarCity?')"
* **Knowledge Graph:** A visual graph with nodes and labeled edges.
* **Nodes:** Tesla, SolarCity, Elon Musk, SpaceX.
* **Edges (Relationships):** `acquired_by`, `founded_by`, `CEO_of`, `operates_in`, `related_to`.
* **Candidate Paths:** A list derived from the graph: `acquired_by`, `founded_by`, `CEO_of`, `operates_in`, `related_to`, etc.
2. **PathHD Hyperdimensional Encoding (Center, Blue Border):**
* **Sub-section 1: Initialize Relation HVs**
* Text: "Initialize Relation HVs" and "Random HV assignment."
* Visual: A list of relations (`acquired_by`, `CEO_of`, etc.) mapped to colored bars representing their initial random hyperdimensional vectors.
* **Sub-section 2: Encode Query HV**
* Text: "Encode Query HV" and "Data encoding."
* Process: The query text is tokenized (`Which`, `company`, `acquired`, `SolarCity`, `?`), encoded, and aggregated into a single "Query HV."
* **Sub-section 3: GHRR Binding & Path Encoding**
* Text: "GHRR Binding & Path Encoding," "Binding (GHRR)," "Path Composition," and "Block-diagonal binding (GHRR)."
* Process: Shows the composition of path HVs using binding (⊗) and permutation (ρ) operations. Example: `Path #1 HV = ρ¹ ⊗ acquired_by`.
* Note: "Captures non-commutative relation binding."
3. **Similarity, Pruning & Reasoning (Right, Yellow Border):**
* **Sub-section 1: Similarity Calculation**
* Text: "Similarity Calculation" and "Cosine Similarity."
* Process: The Query HV is compared via cosine similarity to multiple "Candidate path HVs" (Path #1 HV, Path #2 HV, Path #3 HV...).
* Output: A list of similarity scores (Score #1, Score #2, Score #3...).
* **Sub-section 2: Answer Selection**
* Text: "Answer Selection," "Top-K candidates," "1x LLM re-evaluation," and "Predicted Answer."
* Process: The top-K candidate paths (based on score) are sent to an LLM for re-evaluation, which outputs the final "Predicted Answer."
* **Legend (Bottom Right):** Defines symbols for `entity`, `Relation`, and `Operation`.
### Detailed Analysis
The diagram details a multi-step pipeline for answering a query using hyperdimensional computing:
1. **Input Processing:** A natural language query is parsed. A knowledge graph provides structured data (entities and relations) relevant to the query.
2. **Vector Initialization:** Each relation type in the knowledge graph (e.g., `acquired_by`) is assigned a random, high-dimensional vector (HV).
3. **Query Encoding:** The query text is transformed into a single, dense Query HV.
4. **Path Encoding:** Potential reasoning paths through the knowledge graph (e.g., `Tesla --acquired_by--> ?`) are represented as HVs. This is done using a "Generalized Holographic Reduced Representation (GHRR)" binding operation, which is non-commutative, preserving the order of relations in the path.
5. **Similarity Search:** The system calculates the cosine similarity between the Query HV and all candidate Path HVs. This measures how well each path "matches" the query.
6. **Answer Generation:** The highest-scoring candidate paths are filtered (Top-K) and passed to a Large Language Model (LLM) for final evaluation and answer generation (e.g., "Tesla").
### Key Observations
* **Hybrid Architecture:** The system combines symbolic AI (structured knowledge graphs, explicit paths) with connectionist AI (hyperdimensional vectors, neural LLM).
* **Non-Commutative Binding:** The use of GHRR and permutation (ρ) explicitly encodes the *order* of relations in a path, which is crucial for meaning (e.g., "A acquired by B" vs. "B acquired by A").
* **Two-Stage Reasoning:** A fast, vector-based similarity search prunes the search space, followed by a slower but more powerful LLM re-evaluation for final answer selection.
* **Example Query:** The entire pipeline is illustrated with the concrete example: "Which company acquired SolarCity?" The expected answer, based on the knowledge graph, is "Tesla."
### Interpretation
This diagram presents a novel approach to **neuro-symbolic question answering**. It addresses a key challenge: efficiently searching a vast space of possible reasoning paths in a knowledge graph.
* **What it demonstrates:** The PathHD method translates the symbolic problem of "path finding" into a vector space problem of "similarity search." Hyperdimensional vectors act as a compressed, distributed representation of entire relational paths. This allows for rapid, parallel comparison of many candidate answers.
* **How elements relate:** The Knowledge Graph provides the raw facts. The Hyperdimensional Encoding stage creates a "fuzzy" vector search space from these crisp facts. The Similarity stage performs the core retrieval. The LLM acts as a sophisticated, context-aware filter and answer formatter.
* **Notable implications:** This architecture could offer advantages in **scalability** (handling large KGs) and **interpretability** (the top-scoring paths can be inspected) compared to pure end-to-end neural models. The "non-commutative binding" is a critical technical detail ensuring the semantic integrity of composed paths. The system's effectiveness hinges on the quality of the initial random HVs and the binding operation's ability to create unique, meaningful path representations.