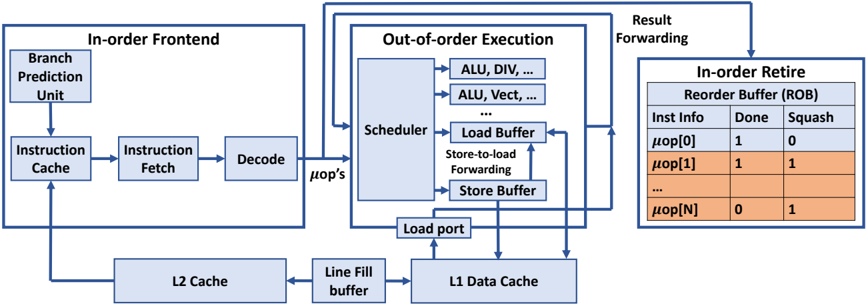
## Diagram: CPU Microarchitecture Pipeline
### Overview
The image is a technical block diagram illustrating the microarchitecture of a modern out-of-order CPU core. It details the flow of instructions from fetch through execution to retirement, highlighting key components and data paths. The diagram is divided into three primary functional blocks and a memory hierarchy subsystem.
### Components/Axes
The diagram is organized into three main rectangular blocks, outlined in blue, and a memory subsystem at the bottom.
**1. In-order Frontend (Left Block):**
* **Components:** Branch Prediction Unit, Instruction Cache, Instruction Fetch, Decode.
* **Flow:** Arrows indicate a sequential flow: Branch Prediction Unit → Instruction Cache → Instruction Fetch → Decode.
* **Output:** The Decode unit outputs "μop's" (micro-operations) to the Out-of-order Execution block.
**2. Out-of-order Execution (Center Block):**
* **Components:** Scheduler, multiple execution units (labeled "ALU, DIV, ...", "ALU, Vect, ..."), Load Buffer, Store Buffer, Store-to-load Forwarding logic, Load port.
* **Flow:** The Scheduler dispatches μops to the execution units. The Load and Store Buffers interface with the memory system. A "Store-to-load Forwarding" path connects the Store Buffer to the Load Buffer.
* **Input/Output:** Receives μops from the Frontend. Sends results via "Result Forwarding" paths to the Scheduler and to the In-order Retire block.
**3. In-order Retire (Right Block):**
* **Component:** Reorder Buffer (ROB).
* **Structure:** A table with three columns: "Inst Info", "Done", "Squash".
* **Data Rows:** The table shows example entries:
| Inst Info | Done | Squash |
|-----------|------|--------|
| `μop[0]` | 1 | 0 |
| `μop[1]` | 1 | 1 |
| `...` | ... | ... |
| `μop[N]` | 0 | 1 |
*Note: Rows for `μop[1]` and `μop[N]` are highlighted in orange.*
**4. Memory Hierarchy (Bottom Section):**
* **Components:** L1 Data Cache, Line Fill buffer, L2 Cache.
* **Flow:** The Load port connects to the L1 Data Cache. The L1 Data Cache connects bidirectionally to the Line Fill buffer, which connects bidirectionally to the L2 Cache. The L2 Cache also has a connection back to the Instruction Cache in the Frontend.
**5. Data Paths & Labels:**
* **"μop's":** Label on the arrow from Decode to the Scheduler.
* **"Result Forwarding":** Label on arrows from execution units back to the Scheduler and to the ROB.
* **"Store-to-load Forwarding":** Label on the path between Store Buffer and Load Buffer.
* **"Load port":** Label on the connection from the Load Buffer to the L1 Data Cache.
### Detailed Analysis
The diagram explicitly maps the flow of a micro-operation (μop) through the pipeline:
1. **Fetch & Decode (In-order):** Instructions are predicted, fetched from the Instruction Cache, and decoded into μops in a strict program order.
2. **Scheduling & Execution (Out-of-order):** μops are sent to the Scheduler, which dispatches them to available execution units (ALU for arithmetic, DIV for division, Vect for vector operations, etc.) as soon as their operands are ready, breaking original program order.
3. **Memory Access:** Load and Store Buffers manage memory operations. The "Store-to-load Forwarding" path is critical for resolving data dependencies where a load needs a value that a preceding, yet-to-commit store will write.
4. **Retirement (In-order):** The Reorder Buffer (ROB) tracks the status of all in-flight μops. It ensures results are committed to the architectural state in the original program order. The table shows:
* `μop[0]` is completed (`Done=1`) and will not be squashed (`Squash=0`).
* `μop[1]` is completed (`Done=1`) but is marked for squash (`Squash=1`), indicating a pipeline flush (e.g., due to a branch misprediction).
* `μop[N]` is not yet completed (`Done=0`) and is also marked for squash (`Squash=1`).
5. **Memory Subsystem:** The L1 Data Cache is the fastest, closest memory. The Line Fill buffer handles cache line fills from the L2 Cache. The L2 Cache is a larger, slower cache that also feeds the Instruction Cache.
### Key Observations
1. **Hybrid In-order/Out-of-order Design:** The frontend and retire stages are in-order, while the execution core is out-of-order. This is a classic design for high-performance CPUs.
2. **Explicit Forwarding Paths:** The diagram emphasizes "Result Forwarding" and "Store-to-load Forwarding," which are essential for minimizing stalls in an out-of-order engine.
3. **ROB State Indication:** The orange highlighting on the `μop[1]` and `μop[N]` rows in the ROB visually groups instructions that are part of the same speculative path that is being squashed.
4. **Abbreviated Labels:** Execution units are listed as "ALU, DIV, ..." and "ALU, Vect, ...", indicating multiple, similar units of each type exist but are not all drawn.
### Interpretation
This diagram is a canonical representation of a **superscalar, out-of-order, speculative execution processor core**. It demonstrates the fundamental principle of decoupling the *apparent* program order (maintained by the Frontend and Retire stages) from the *actual* execution order (managed by the Scheduler in the Execution core).
The data suggests a focus on **instruction-level parallelism (ILP)**. The Scheduler's role is to find and exploit independent instructions to keep the multiple execution units busy. The ROB is the critical component that enables this speculation—it allows the processor to execute instructions ahead of time and then "undo" the effects (squash) if the speculation was wrong (e.g., a branch was mispredicted).
The memory hierarchy connections show a **non-blocking cache** design, where the Line Fill buffer allows the cache to service multiple outstanding misses. The direct link from L2 Cache to Instruction Cache highlights the importance of feeding the frontend with instructions to sustain the high throughput of the execution core.
**Notable Anomaly/Detail:** The `Squash=1` flag on a completed `μop[1]` is particularly insightful. It shows that even instructions that have finished execution can be discarded if they belong to a speculative path that is later invalidated. This is a core concept of speculative execution.