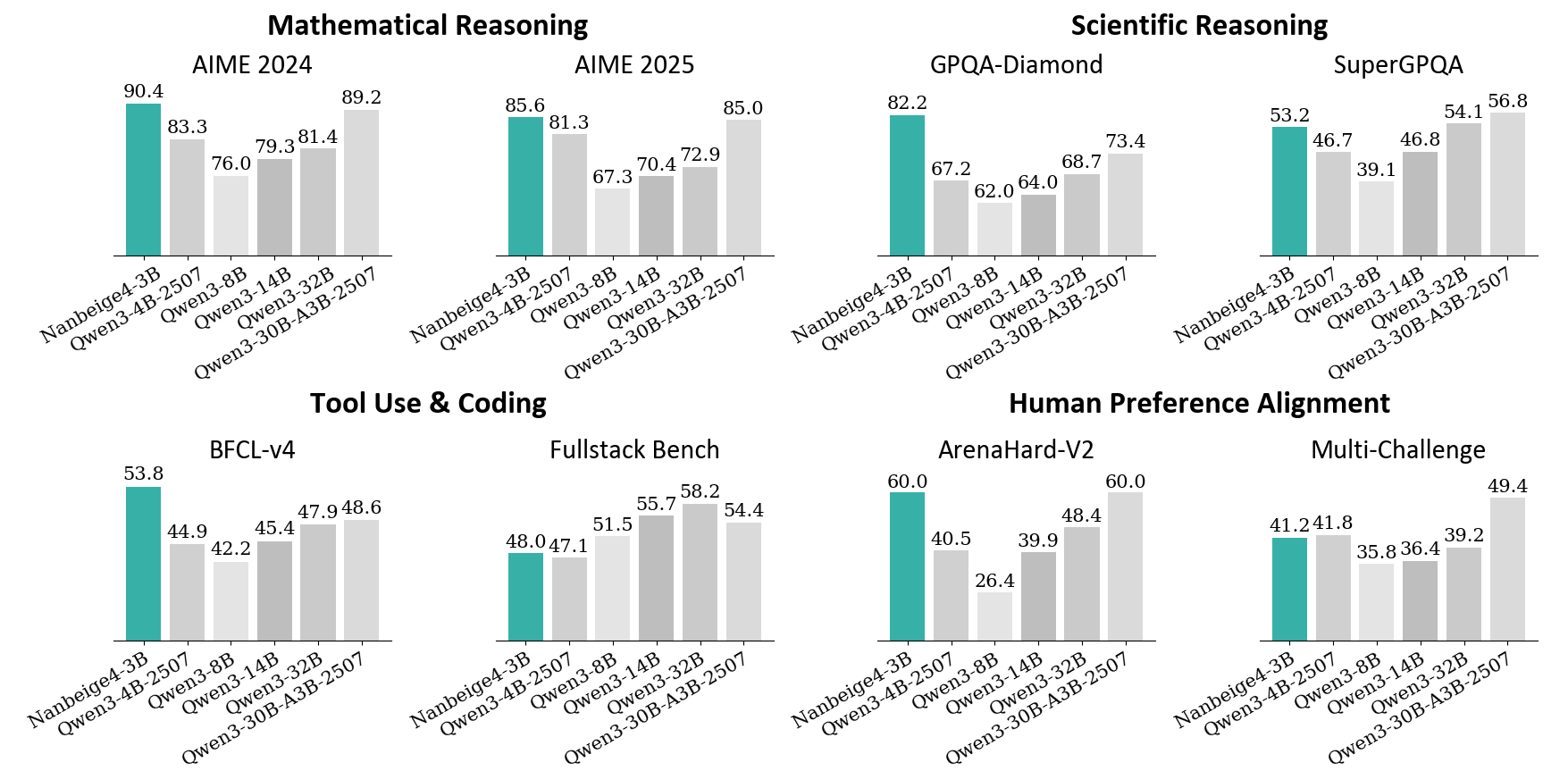
## Bar Charts: Model Performance Across Benchmarks
### Overview
The image presents a series of bar charts comparing the performance of different language models (Nanbeige4-3B, Qwen3-4B-2507, Qwen3-8B, Qwen3-14B, Qwen3-32B, Qwen3-30B-A3B-2507) across various benchmarks. The benchmarks are grouped into four categories: Mathematical Reasoning, Scientific Reasoning, Tool Use & Coding, and Human Preference Alignment. Each category contains two specific benchmarks. The y-axis represents the score achieved on each benchmark, but the scale is not explicitly labeled, implying it's a percentage or a standardized score.
### Components/Axes
* **X-axis:** Categorical axis representing the different language models: Nanbeige4-3B, Qwen3-4B-2507, Qwen3-8B, Qwen3-14B, Qwen3-32B, Qwen3-30B-A3B-2507.
* **Y-axis:** Numerical axis representing the score achieved by each model on the benchmark. The scale is not explicitly labeled.
* **Bar Color:** Teal bars represent the "Nanbeige4-3B" model, while light gray bars represent the "Qwen" models.
* **Chart Titles:** Each chart has a title indicating the benchmark category and specific benchmark name.
### Detailed Analysis
**1. Mathematical Reasoning**
* **AIME 2024:**
* Nanbeige4-3B: 90.4
* Qwen3-4B-2507: 83.3
* Qwen3-8B: 76.0
* Qwen3-14B: 79.3
* Qwen3-32B: 81.4
* Qwen3-30B-A3B-2507: 89.2
* Trend: Nanbeige4-3B has the highest score, followed by Qwen3-30B-A3B-2507. Qwen3-8B has the lowest score.
* **AIME 2025:**
* Nanbeige4-3B: 85.6
* Qwen3-4B-2507: 81.3
* Qwen3-8B: 67.3
* Qwen3-14B: 70.4
* Qwen3-32B: 72.9
* Qwen3-30B-A3B-2507: 85.0
* Trend: Nanbeige4-3B has the highest score, closely followed by Qwen3-30B-A3B-2507. Qwen3-8B has the lowest score.
**2. Scientific Reasoning**
* **GPQA-Diamond:**
* Nanbeige4-3B: 82.2
* Qwen3-4B-2507: 67.2
* Qwen3-8B: 62.0
* Qwen3-14B: 64.0
* Qwen3-32B: 68.7
* Qwen3-30B-A3B-2507: 73.4
* Trend: Nanbeige4-3B significantly outperforms the other models. Qwen3-8B has the lowest score.
* **SuperGPQA:**
* Nanbeige4-3B: 53.2
* Qwen3-4B-2507: 46.7
* Qwen3-8B: 39.1
* Qwen3-14B: 46.8
* Qwen3-32B: 54.1
* Qwen3-30B-A3B-2507: 56.8
* Trend: Qwen3-30B-A3B-2507 has the highest score, closely followed by Qwen3-32B. Qwen3-8B has the lowest score.
**3. Tool Use & Coding**
* **BFCL-v4:**
* Nanbeige4-3B: 53.8
* Qwen3-4B-2507: 44.9
* Qwen3-8B: 42.2
* Qwen3-14B: 45.4
* Qwen3-32B: 47.9
* Qwen3-30B-A3B-2507: 48.6
* Trend: Nanbeige4-3B has the highest score. Qwen3-8B has the lowest score.
* **Fullstack Bench:**
* Nanbeige4-3B: 48.0
* Qwen3-4B-2507: 47.1
* Qwen3-8B: 51.5
* Qwen3-14B: 55.7
* Qwen3-32B: 58.2
* Qwen3-30B-A3B-2507: 54.4
* Trend: Qwen3-32B has the highest score. Nanbeige4-3B has one of the lowest scores.
**4. Human Preference Alignment**
* **ArenaHard-V2:**
* Nanbeige4-3B: 60.0
* Qwen3-4B-2507: 40.5
* Qwen3-8B: 26.4
* Qwen3-14B: 39.9
* Qwen3-32B: 48.4
* Qwen3-30B-A3B-2507: 60.0
* Trend: Nanbeige4-3B and Qwen3-30B-A3B-2507 have the highest scores. Qwen3-8B has the lowest score.
* **Multi-Challenge:**
* Nanbeige4-3B: 41.2
* Qwen3-4B-2507: 41.8
* Qwen3-8B: 35.8
* Qwen3-14B: 36.4
* Qwen3-32B: 39.2
* Qwen3-30B-A3B-2507: 49.4
* Trend: Qwen3-30B-A3B-2507 has the highest score. Qwen3-8B has the lowest score.
### Key Observations
* Nanbeige4-3B consistently performs well across most benchmarks, often achieving the highest or near-highest scores.
* Qwen3-8B tends to have the lowest scores across many benchmarks.
* Qwen3-30B-A3B-2507 shows strong performance, often competing with Nanbeige4-3B.
* The performance of the Qwen models varies depending on the specific benchmark.
### Interpretation
The data suggests that Nanbeige4-3B is a strong general-purpose language model, demonstrating high performance across a variety of tasks. Qwen3-30B-A3B-2507 also shows promise. The varying performance of the other Qwen models highlights the importance of model selection based on the specific task at hand. The consistent underperformance of Qwen3-8B may indicate limitations in its architecture or training data. The benchmarks cover a range of cognitive abilities, including mathematical reasoning, scientific reasoning, tool use, coding, and human preference alignment, providing a comprehensive evaluation of the models' capabilities.