\n
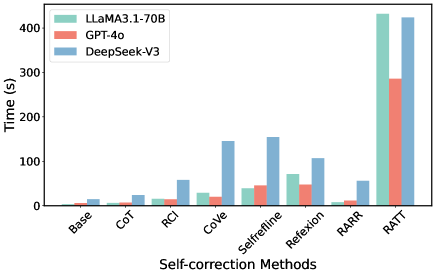
## Bar Chart: Self-Correction Method Performance
### Overview
The image presents a bar chart comparing the execution time (in seconds) of three different language models – LLaMA3.1-70B, GPT-4o, and DeepSeek-V3 – across various self-correction methods. The x-axis represents the self-correction methods, and the y-axis represents the time taken in seconds.
### Components/Axes
* **X-axis Title:** "Self-correction Methods"
* **Y-axis Title:** "Time (s)"
* **Legend:** Located in the top-left corner.
* LLaMA3.1-70B (Light Green)
* GPT-4o (Light Red)
* DeepSeek-V3 (Light Blue)
* **Self-correction Methods (X-axis labels):** Base, CoT, RCI, CoVe, Selfrefine, Reflexion, RARR, RATT.
### Detailed Analysis
The chart consists of grouped bar plots for each self-correction method, with each group representing the execution time of the three models.
* **Base:**
* LLaMA3.1-70B: Approximately 1 second.
* GPT-4o: Approximately 2 seconds.
* DeepSeek-V3: Approximately 1 second.
* **CoT:**
* LLaMA3.1-70B: Approximately 3 seconds.
* GPT-4o: Approximately 4 seconds.
* DeepSeek-V3: Approximately 2 seconds.
* **RCI:**
* LLaMA3.1-70B: Approximately 1 second.
* GPT-4o: Approximately 2 seconds.
* DeepSeek-V3: Approximately 1 second.
* **CoVe:**
* LLaMA3.1-70B: Approximately 7 seconds.
* GPT-4o: Approximately 2 seconds.
* DeepSeek-V3: Approximately 15 seconds.
* **Selfrefine:**
* LLaMA3.1-70B: Approximately 2 seconds.
* GPT-4o: Approximately 3 seconds.
* DeepSeek-V3: Approximately 15 seconds.
* **Reflexion:**
* LLaMA3.1-70B: Approximately 6 seconds.
* GPT-4o: Approximately 8 seconds.
* DeepSeek-V3: Approximately 11 seconds.
* **RARR:**
* LLaMA3.1-70B: Approximately 1 second.
* GPT-4o: Approximately 1 second.
* DeepSeek-V3: Approximately 2 seconds.
* **RATT:**
* LLaMA3.1-70B: Approximately 420 seconds.
* GPT-4o: Approximately 280 seconds.
* DeepSeek-V3: Approximately 420 seconds.
**Trends:**
* For most self-correction methods, the execution times are relatively low (under 10 seconds).
* DeepSeek-V3 generally exhibits higher execution times for CoVe and Selfrefine compared to the other two models.
* RATT shows significantly higher execution times for all three models, exceeding 250 seconds.
* LLaMA3.1-70B and DeepSeek-V3 have identical execution times for Base and RCI.
### Key Observations
* The RATT method is a clear outlier, taking substantially longer than any other method for all models.
* DeepSeek-V3 appears to be the slowest model for CoVe and Selfrefine.
* GPT-4o is generally faster than LLaMA3.1-70B for Base, CoT, and Reflexion.
### Interpretation
The chart demonstrates the performance of different language models when employing various self-correction techniques. The significant increase in execution time for the RATT method suggests that it is a computationally expensive process, potentially due to its complexity or the amount of data it processes. The variations in execution times between models for specific methods (e.g., DeepSeek-V3 for CoVe and Selfrefine) indicate that the efficiency of self-correction techniques can be model-dependent. The relatively low execution times for methods like Base, CoT, and RCI suggest they are more efficient and could be preferred in scenarios where speed is critical. The data suggests a trade-off between the complexity of the self-correction method and the execution time, with more sophisticated methods like RATT requiring significantly more computational resources. The differences in performance between the models highlight the importance of considering model-specific characteristics when selecting self-correction techniques.