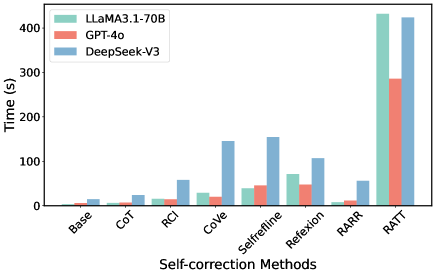
## Bar Chart: Performance Comparison of Self-Correction Methods Across Three Large Language Models
### Overview
The image is a grouped bar chart comparing the execution time (in seconds) of eight different self-correction methods when applied to three distinct large language models (LLMs). The chart visually demonstrates the computational cost associated with each method for each model.
### Components/Axes
* **Chart Type:** Grouped Bar Chart.
* **X-Axis (Horizontal):** Labeled **"Self-correction Methods"**. It lists eight categorical methods:
1. Base
2. CoT (Chain-of-Thought)
3. RCI (Recursive Critique and Improve)
4. CoVe (Chain-of-Verification)
5. SelfRefine
6. Reflexion
7. RARR (Rethink and Rewrite)
8. RATT (Recursive Abstractive Thought Tree)
* **Y-Axis (Vertical):** Labeled **"Time (s)"**. It represents execution time in seconds, with a linear scale from 0 to 400, marked at intervals of 100 (0, 100, 200, 300, 400).
* **Legend:** Located in the **top-left corner** of the chart area. It defines the three data series by color:
* **Teal/Green:** LLaMA3.1-70B
* **Salmon/Orange:** GPT-4o
* **Blue:** DeepSeek-V3
### Detailed Analysis
The following values are approximate, derived from visual inspection of the bar heights against the y-axis scale.
**Trend Verification:** For all three models, the general trend is that time increases significantly for the more complex, iterative methods (CoVe, SelfRefine, Reflexion, RATT) compared to the baseline and simpler prompting methods (Base, CoT, RCI, RARR). The RATT method is a clear outlier, consuming the most time by a large margin for every model.
**Data Points by Method (Approximate Time in Seconds):**
1. **Base:**
* LLaMA3.1-70B: ~10s
* GPT-4o: ~5s
* DeepSeek-V3: ~20s
2. **CoT:**
* LLaMA3.1-70B: ~15s
* GPT-4o: ~10s
* DeepSeek-V3: ~25s
3. **RCI:**
* LLaMA3.1-70B: ~20s
* GPT-4o: ~15s
* DeepSeek-V3: ~60s
4. **CoVe:**
* LLaMA3.1-70B: ~30s
* GPT-4o: ~25s
* DeepSeek-V3: ~150s
5. **SelfRefine:**
* LLaMA3.1-70B: ~40s
* GPT-4o: ~50s
* DeepSeek-V3: ~160s
6. **Reflexion:**
* LLaMA3.1-70B: ~70s
* GPT-4o: ~50s
* DeepSeek-V3: ~110s
7. **RARR:**
* LLaMA3.1-70B: ~10s
* GPT-4o: ~10s
* DeepSeek-V3: ~60s
8. **RATT:**
* LLaMA3.1-70B: ~430s (exceeds the 400s axis mark)
* GPT-4o: ~290s
* DeepSeek-V3: ~420s (exceeds the 400s axis mark)
### Key Observations
1. **Dominant Outlier:** The **RATT** method is dramatically more time-intensive than all others for every model, with times roughly 3-10x higher than the next most expensive method (SelfRefine/CoVe for DeepSeek-V3).
2. **Model-Specific Patterns:**
* **DeepSeek-V3 (Blue)** consistently shows the highest or near-highest execution time for most methods, particularly for CoVe, SelfRefine, and RARR.
* **GPT-4o (Salmon)** generally exhibits the lowest execution times across the board, with the notable exception of the RATT method.
* **LLaMA3.1-70B (Teal)** often falls between the other two models, but it records the single highest time for RATT.
3. **Method Clustering:** Methods can be loosely grouped by computational cost:
* **Low Cost:** Base, CoT, RARR (all models < ~60s).
* **Medium Cost:** RCI, Reflexion (times vary by model, up to ~110s).
* **High Cost:** CoVe, SelfRefine (significantly higher for DeepSeek-V3).
* **Very High Cost:** RATT (extremely high for all models).
### Interpretation
This chart provides a clear quantitative comparison of the **computational overhead** introduced by various self-correction techniques in LLMs. The data suggests a fundamental trade-off: more sophisticated, recursive, or multi-step self-correction methods (like RATT, CoVe, SelfRefine) incur a substantial time penalty.
The significant variation between models (e.g., DeepSeek-V3's high cost for CoVe vs. GPT-4o's relative efficiency) implies differences in model architecture, inference optimization, or the specific implementation of these methods for each model. The extreme cost of RATT indicates it is likely a highly complex, tree-based search or deliberation process.
For a practitioner, this information is critical for selecting a self-correction method. If latency is a primary constraint, methods like CoT or RARR are preferable. If maximum accuracy is the goal and computational resources are abundant, a method like RATT might be justified, but its cost must be weighed against potential gains. The chart effectively visualizes that "better" self-correction is not free—it is paid for in time.