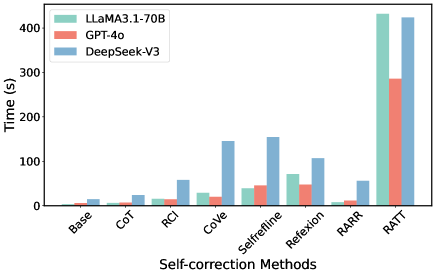
## Bar Chart: Self-Correction Method Performance Comparison
### Overview
The chart compares the execution time (in seconds) of three large language models (LLMs) across nine self-correction methods. The models are LLaMA3.1-70B (green), GPT-4o (red), and DeepSeek-V3 (blue). Each method is represented by grouped bars showing relative performance differences.
### Components/Axes
- **X-axis (Self-correction Methods)**: Base, CoT, RCI, CoVe, Selfrefine, Reflexion, RARR, RATT (left to right)
- **Y-axis (Time in seconds)**: Logarithmic scale from 0 to 400s
- **Legend**: Top-left corner with color-coded model identifiers
- **Bar Groups**: Three bars per method (green/red/blue) representing model performance
### Detailed Analysis
1. **Base Method**:
- LLaMA3.1-70B: ~5s
- GPT-4o: ~3s
- DeepSeek-V3: ~10s
2. **CoT**:
- LLaMA3.1-70B: ~8s
- GPT-4o: ~5s
- DeepSeek-V3: ~15s
3. **RCI**:
- LLaMA3.1-70B: ~12s
- GPT-4o: ~8s
- DeepSeek-V3: ~30s
4. **CoVe**:
- LLaMA3.1-70B: ~25s
- GPT-4o: ~15s
- DeepSeek-V3: ~140s
5. **Selfrefine**:
- LLaMA3.1-70B: ~35s
- GPT-4o: ~45s
- DeepSeek-V3: ~150s
6. **Reflexion**:
- LLaMA3.1-70B: ~70s
- GPT-4o: ~50s
- DeepSeek-V3: ~105s
7. **RARR**:
- LLaMA3.1-70B: ~5s
- GPT-4o: ~8s
- DeepSeek-V3: ~50s
8. **RATT**:
- LLaMA3.1-70B: ~420s
- GPT-4o: ~280s
- DeepSeek-V3: ~410s
### Key Observations
1. **LLaMA3.1-70B** consistently shows the highest execution times across all methods except Base and RARR
2. **GPT-4o** demonstrates the fastest performance in 7/8 methods, with RATT being the notable exception
3. **DeepSeek-V3** maintains mid-range performance, with significant spikes in CoVe and RATT
4. **RATT method** shows extreme time requirements for all models, with LLaMA3.1-70B being the slowest
5. **Base method** has the tightest performance spread (~3s difference between fastest/slowest model)
### Interpretation
The data reveals fundamental differences in how these models handle self-correction tasks:
- **GPT-4o** demonstrates superior efficiency in most methods, suggesting optimized implementation or architectural advantages
- **LLaMA3.1-70B**'s poor performance in complex methods (CoVe, RATT) indicates potential limitations in handling iterative reasoning tasks
- The **RATT outlier** suggests this method introduces unique computational demands that disproportionately affect LLaMA3.1-70B
- Performance gaps widen with method complexity, highlighting trade-offs between correction capability and computational cost
The chart implies that while larger models (LLaMA3.1-70B) may have greater theoretical capacity, practical implementation efficiency varies significantly between architectures. The RATT method's extreme time requirements across all models warrant further investigation into its computational bottlenecks.