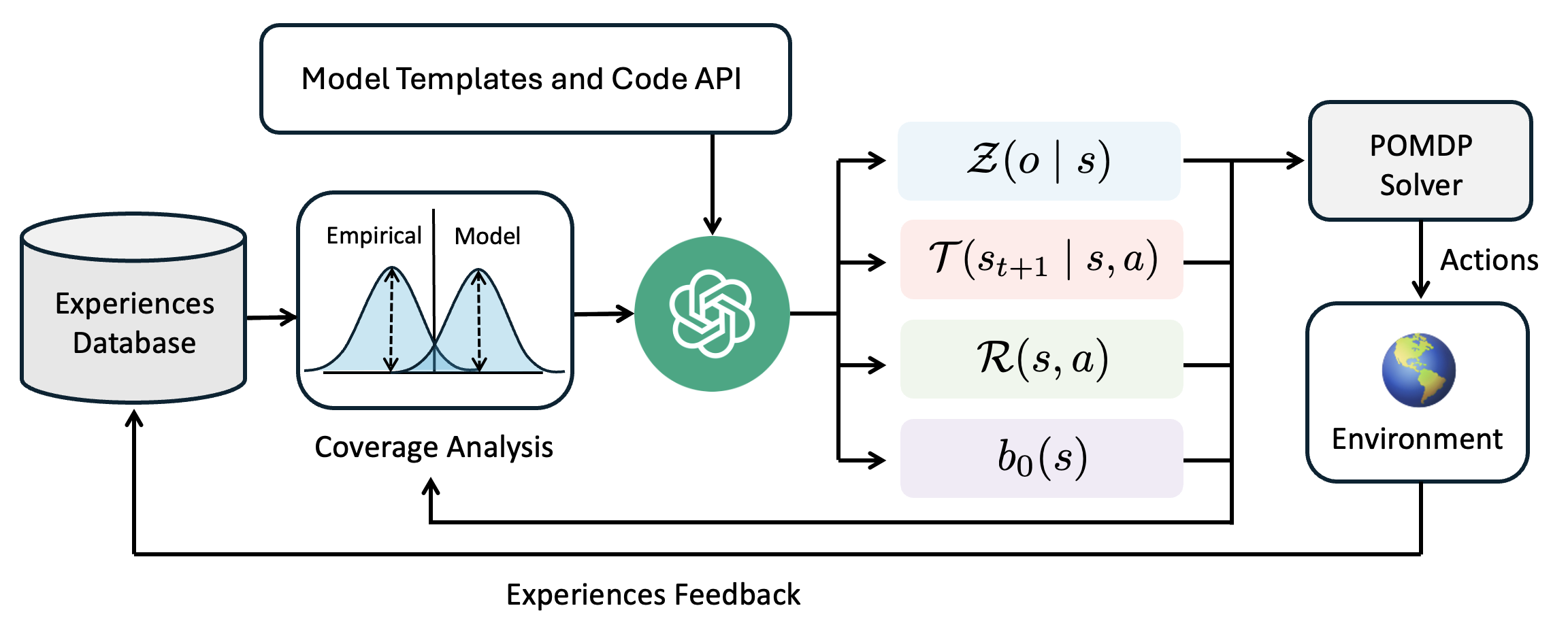
## Flowchart: System Architecture for Experiential Learning with POMDP
### Overview
The diagram illustrates a closed-loop system integrating experiential learning, probabilistic modeling, and decision-making via a Partially Observable Markov Decision Process (POMDP). Key components include an Experiences Database, coverage analysis, model templates, and an environment interaction loop.
### Components/Axes
1. **Nodes**:
- **Experiences Database**: Cylindrical icon storing empirical data.
- **Coverage Analysis**: Box comparing Empirical and Model distributions (bell curves).
- **Model Templates and Code API**: Central green node with a knot symbol, acting as a processing hub.
- **POMDP Solver**: Box generating Actions based on environmental feedback.
- **Environment**: Globe icon representing the external system being modeled.
2. **Edges**:
- **Experiences Feedback**: Bidirectional arrow connecting Environment to Experiences Database.
- **Model Templates and Code API** links to:
- **Z(o | s)**: Observation function (blue box).
- **T(st+1 | s, a)**: Transition function (pink box).
- **R(s, a)**: Reward function (green box).
- **b0(s)**: Baseline policy (purple box).
### Detailed Analysis
- **Empirical vs. Model Distributions**: Coverage Analysis visually compares two probability distributions, suggesting iterative refinement of models against real-world data.
- **POMDP Components**:
- **Z(o | s)**: Maps observations to hidden states.
- **T(st+1 | s, a)**: Defines state transitions given actions.
- **R(s, a)**: Quantifies rewards for state-action pairs.
- **b0(s)**: Represents a default policy for state initialization.
- **Feedback Loop**: Environment outputs influence the Experiences Database, enabling continuous model updates.
### Key Observations
1. **Bidirectional Flow**: The feedback loop between Environment and Experiences Database emphasizes adaptive learning.
2. **POMDP Integration**: The solver synthesizes observation, transition, reward, and baseline policies to generate Actions.
3. **Symbolic Representation**: The green knot symbol may denote modularity or composability in the Code API.
### Interpretation
This architecture represents a reinforcement learning system where:
- **Experiential Data** (Empirical) trains models to approximate idealized distributions (Model).
- The **POMDP Solver** uses probabilistic functions to navigate uncertainty in the Environment.
- The **Feedback Loop** ensures the system evolves by incorporating real-world outcomes into the Experiences Database.
The diagram highlights a cyclical process of data collection, model refinement, and decision-making under partial observability, typical of advanced AI/ML pipelines.