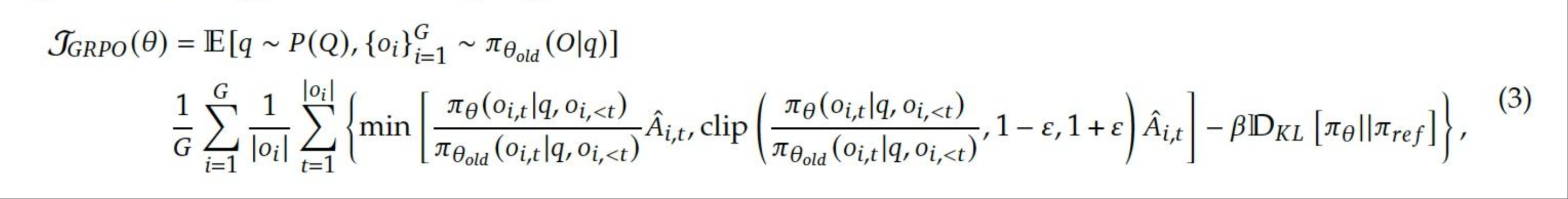\n
## Mathematical Equation: CRPO Loss Function
### Overview
The image presents a complex mathematical equation representing the CRPO (Constrained Reinforcement Policy Optimization) loss function. It appears to be a formula used in reinforcement learning, likely for training an agent to optimize a policy while adhering to certain constraints.
### Components/Axes
The equation is presented as a single block of text with several mathematical symbols and notations. Key components include:
* **Variables:** θ (theta), G, i, j, π (pi), Â (A hat), ε (epsilon), ρ (rho), x, q, ct, r<sub>t</sub>
* **Functions/Operators:** E[.], P(.), min[.], clip[.], Σ (summation)
* **Notations:** 𝒩<sub>RP0</sub>(θ), 𝒩<sub>θ,ld</sub>, D<sub>KL</sub>
* **Equation Number:** (3) located in the top-right corner.
### Detailed Analysis / Content Details
The equation can be transcribed as follows:
𝒩<sub>RP0</sub>(θ) = E[<sub>q</sub> ~ P(<sub>q</sub> | {<sub>φi</sub>}<sup>G</sup><sub>i=1</sub> ~ 𝒩<sub>θ,ld</sub>(<sub>q</sub>|<sub>φ</sub>)]
= (1/G) * Σ<sub>i=1</sub><sup>G</sup> * (1/|<sub>φi</sub>|) * Σ<sub>j=1</sub><sup>|<sub>φi</sub>|</sup> min[ (π<sub>θ</sub>(c<sub>j</sub>|q, <sub>φi</sub>, c<sub><t</sub>) / 𝒩<sub>θ,ld</sub>(<sub>q</sub>|<sub>φi</sub>, <sub>φ</sub>)) * Â<sub>i,j</sub>, clip( (π<sub>θ</sub>(c<sub>j</sub>|q, <sub>φi</sub>, c<sub><t</sub>) / 𝒩<sub>θ,ld</sub>(<sub>q</sub>|<sub>φi</sub>, <sub>φ</sub>)), 1 - ε, 1 + ε) + Â<sub>i,j</sub> ] - βD<sub>KL</sub>[π<sub>θ</sub>||r<sub>t</sub>]
### Key Observations
The equation involves nested summations and a minimization operation. The presence of the KL divergence (D<sub>KL</sub>) suggests a regularization term to prevent the policy from deviating too far from a reference policy (r<sub>t</sub>). The clipping function limits the ratio of probabilities to a specified range (1 - ε, 1 + ε), which is a common technique in policy gradient methods to improve stability. The notation 𝒩<sub>θ,ld</sub> suggests a learned distribution.
### Interpretation
This equation defines a loss function for constrained reinforcement learning. The goal is to optimize a policy (represented by θ) such that it maximizes the expected reward (E[.]) while satisfying certain constraints. The constraints are likely related to the learned distribution 𝒩<sub>θ,ld</sub> and the KL divergence term. The equation attempts to balance exploration (through the policy π<sub>θ</sub>) with exploitation (through the advantage function Â<sub>i,j</sub>) while ensuring that the policy remains within acceptable bounds. The parameters β and ε control the strength of the constraints and the clipping range, respectively. The equation is a sophisticated approach to policy optimization, designed to address the challenges of instability and constraint satisfaction in reinforcement learning. The equation is a mathematical formulation, and its practical meaning is dependent on the specific reinforcement learning problem it is applied to.