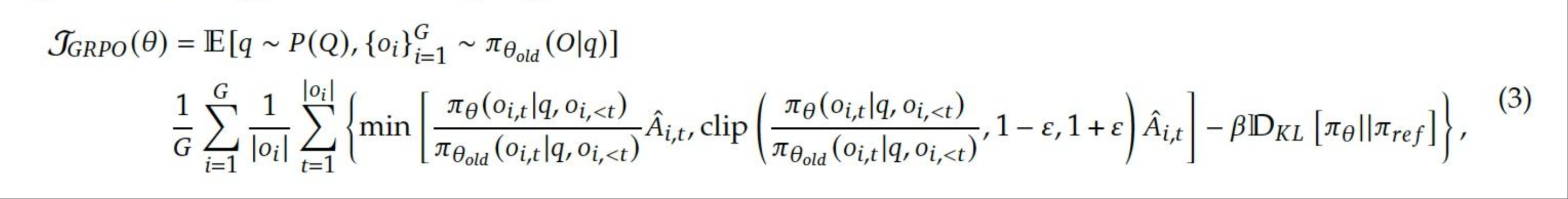The image contains a mathematical equation written in LaTeX notation. Below is the extracted textual information with detailed analysis:
---
### **Equation Structure**
1. **Primary Equation**:
- **Label**: `(3)` (appears at the end of the equation).
- **Components**:
- **Left-Hand Side (LHS)**:
`\mathcal{J}_{GRPO}(\theta)`
- Represents a functional or objective related to the GRPO (Generalized Reinforcement Policy Optimization) framework.
- **Right-Hand Side (RHS)**:
`\mathbb{E}[q \sim P(Q), \{o_i\}_{i=1}^G \sim \pi_{\theta_{old}}(O|q)]`
- Denotes an expectation over:
- `q`: A variable drawn from a distribution `P(Q)`.
- `\{o_i\}_{i=1}^G`: A sequence of observations/actions indexed by `i` from `1` to `G`, sampled from the policy `\pi_{\theta_{old}}(O|q)`.
2. **Expanded Form**:
- **Summation and Minimization**:
```latex
\frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \left\{ \min \left[ \frac{\pi_\theta(o_{i,t}|q, o_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q, o_{i,<t})} \hat{A}_{i,t}, \text{clip} \left( \frac{\pi_\theta(o_{i,t}|q, o_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q, o_{i,<t})}, 1-\epsilon, 1+\epsilon \right) \hat{A}_{i,t} \right] - \beta \mathbb{D}_{KL}[\pi_\theta || \pi_{ref}] \right\},
```
- **Key Terms**:
- `G`: Total number of episodes or sequences.
- `|o_i|`: Length of the `i`-th episode/sequence.
- `\pi_\theta`: Current policy parameterized by `\theta`.
- `\pi_{\theta_{old}}`: Previous policy (reference policy).
- `\hat{A}_{i,t}`: Estimated advantage function for the `t`-th step in the `i`-th episode.
- `\epsilon`: Clipping parameter to bound the ratio of policy updates.
- `\beta`: Scaling factor for the KL divergence penalty.
- `\mathbb{D}_{KL}[\pi_\theta || \pi_{ref}]`: Kullback-Leibler divergence between the current policy `\pi_\theta` and a reference policy `\pi_{ref}`.
---
### **Key Observations**
- The equation defines an **objective function** (`\mathcal{J}_{GRPO}(\theta)`) for optimizing a reinforcement learning policy.
- The expectation term aggregates over trajectories `q` and sequences of actions `o_i`, emphasizing the role of **behavioral cloning** (`\pi_{\theta_{old}}`) and **policy improvement** (`\pi_\theta`).
- The minimization term balances:
1. A **ratio of policy probabilities** (proximal constraint via clipping).
2. A **KL divergence penalty** to prevent excessive divergence from a reference policy.
---
### **Non-English Text**
- **None**: All symbols and terms are standard mathematical notation in English technical contexts.
---
### **Critical Notes**
- **No chart/diagram**: The image is purely symbolic (no visual data points, axes, or legends).
- **Equation Purpose**: Likely part of a reinforcement learning algorithm, specifically GRPO, which combines policy optimization with KL divergence regularization.
- **Assumptions**: Requires familiarity with RL concepts (e.g., advantage functions, KL divergence, policy optimization).
---
This extraction captures all textual and symbolic content from the image. Let me know if further clarification is needed!