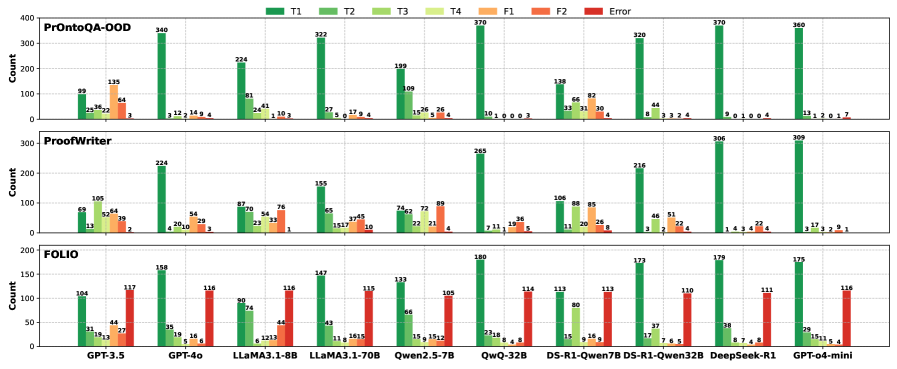
## Bar Chart: Performance Comparison of Language Models
### Overview
The image presents a grouped bar chart comparing the performance of several language models (GPT-3.5, GPT-4, LLaMA, Qwen, DeepSeek, and others) across three datasets: ProntoQA-OOD, ProofWriter, and FOLIO. The performance is categorized into five types of responses: T1, T2, T3, T4, F1, and Error. The y-axis represents the "Count" of responses, ranging from 0 to 400.
### Components/Axes
* **Y-axis:** "Count" (Scale: 0 to 400, increments of 50)
* **X-axis:** Language Models (GPT-3.5, GPT-4, LLaMA3.1-8B, LLaMA3.1-70B, Qwen2.5-7B, QwQ-32B, DS-R1-Qwen7B, DS-R1-Qwen32B, DeepSeek-R1, GPT-04-mini)
* **Datasets:** Three rows represent three datasets: ProntoQA-OOD, ProofWriter, and FOLIO.
* **Legend:** Located at the top-left corner, defining the color-coding for response types:
* T1 (Green)
* T2 (Light Green)
* T3 (Yellow)
* T4 (Orange)
* F1 (Red)
* Error (Dark Red)
### Detailed Analysis or Content Details
**1. ProntoQA-OOD Dataset (Top Row)**
* **GPT-3.5:** T1: ~25, T2: ~99, T3: ~115, T4: ~340, F1: ~8, Error: ~3
* **GPT-4:** T1: ~1, T2: ~14, T3: ~12, T4: ~224, F1: ~41, Error: ~1
* **LLaMA3.1-8B:** T1: ~24, T2: ~41, T3: ~27, T4: ~322, F1: ~109, Error: ~1
* **LLaMA3.1-70B:** T1: ~1, T2: ~17, T3: ~15, T4: ~199, F1: ~136, Error: ~26
* **Qwen2.5-7B:** T1: ~4, T2: ~11, T3: ~22, T4: ~72, F1: ~109, Error: ~4
* **QwQ-32B:** T1: ~0, T2: ~8, T3: ~33, T4: ~370, F1: ~128, Error: ~0
* **DS-R1-Qwen7B:** T1: ~0, T2: ~30, T3: ~82, T4: ~320, F1: ~84, Error: ~8
* **DS-R1-Qwen32B:** T1: ~0, T2: ~22, T3: ~44, T4: ~306, F1: ~79, Error: ~2
* **DeepSeek-R1:** T1: ~0, T2: ~4, T3: ~51, T4: ~770, F1: ~38, Error: ~0
* **GPT-04-mini:** T1: ~1, T2: ~13, T3: ~12, T4: ~360, F1: ~82, Error: ~1
**2. ProofWriter Dataset (Middle Row)**
* **GPT-3.5:** T1: ~64, T2: ~52, T3: ~74, T4: ~105, F1: ~224, Error: ~2
* **GPT-4:** T1: ~56, T2: ~39, T3: ~50, T4: ~224, F1: ~24, Error: ~10
* **LLaMA3.1-8B:** T1: ~87, T2: ~70, T3: ~54, T4: ~155, F1: ~87, Error: ~2
* **LLaMA3.1-70B:** T1: ~76, T2: ~65, T3: ~45, T4: ~195, F1: ~151, Error: ~17
* **Qwen2.5-7B:** T1: ~72, T2: ~74, T3: ~69, T4: ~227, F1: ~106, Error: ~8
* **QwQ-32B:** T1: ~71, T2: ~36, T3: ~24, T4: ~265, F1: ~85, Error: ~6
* **DS-R1-Qwen7B:** T1: ~41, T2: ~20, T3: ~11, T4: ~216, F1: ~88, Error: ~24
* **DS-R1-Qwen32B:** T1: ~51, T2: ~22, T3: ~7, T4: ~306, F1: ~79, Error: ~4
* **DeepSeek-R1:** T1: ~44, T2: ~22, T3: ~4, T4: ~770, F1: ~38, Error: ~0
* **GPT-04-mini:** T1: ~17, T2: ~13, T3: ~3, T4: ~309, F1: ~82, Error: ~3
**3. FOLIO Dataset (Bottom Row)**
* **GPT-3.5:** T1: ~14, T2: ~117, T3: ~115, T4: ~150, F1: ~44, Error: ~29
* **GPT-4:** T1: ~19, T2: ~116, T3: ~116, T4: ~118, F1: ~19, Error: ~15
* **LLaMA3.1-8B:** T1: ~62, T2: ~114, T3: ~88, T4: ~167, F1: ~74, Error: ~11
* **LLaMA3.1-70B:** T1: ~44, T2: ~147, T3: ~115, T4: ~119, F1: ~66, Error: ~18
* **Qwen2.5-7B:** T1: ~15, T2: ~133, T3: ~105, T4: ~180, F1: ~114, Error: ~9
* **QwQ-32B:** T1: ~18, T2: ~114, T3: ~113, T4: ~180, F1: ~110, Error: ~15
* **DS-R1-Qwen7B:** T1: ~7, T2: ~95, T3: ~80, T4: ~179, F1: ~110, Error: ~14
* **DS-R1-Qwen32B:** T1: ~8, T2: ~74, T3: ~38, T4: ~175, F1: ~111, Error: ~8
* **DeepSeek-R1:** T1: ~8, T2: ~45, T3: ~38, T4: ~175, F1: ~110, Error: ~7
* **GPT-04-mini:** T1: ~11, T2: ~116, T3: ~115, T4: ~175, F1: ~116, Error: ~5
### Key Observations
* **T4 Dominance:** Across all datasets and models, the "T4" response type consistently has the highest count, indicating it's the most frequent type of response generated.
* **Error Rates:** Error rates are generally low, but vary significantly between models. DeepSeek-R1 consistently shows very low error rates.
* **Model Performance Variation:** GPT-4 and DeepSeek-R1 generally exhibit higher counts in T4 and lower error rates compared to other models.
* **Dataset Impact:** The distribution of response types varies across datasets. For example, F1 responses are more prominent in the ProofWriter dataset.
### Interpretation
This chart provides a comparative analysis of language model performance across different datasets, categorized by response types. The dominance of "T4" suggests that this response type represents a common or default behavior of these models. The low error rates across most models indicate a generally high level of reliability. The variations in performance between models and datasets highlight the importance of selecting the appropriate model for a specific task. The consistent strong performance of DeepSeek-R1 and GPT-4 suggests they are robust and reliable choices. The differences between the 8B and 70B versions of LLaMA indicate that model size impacts performance, but not always linearly. The chart allows for a nuanced understanding of the strengths and weaknesses of each model, enabling informed decision-making in natural language processing applications.