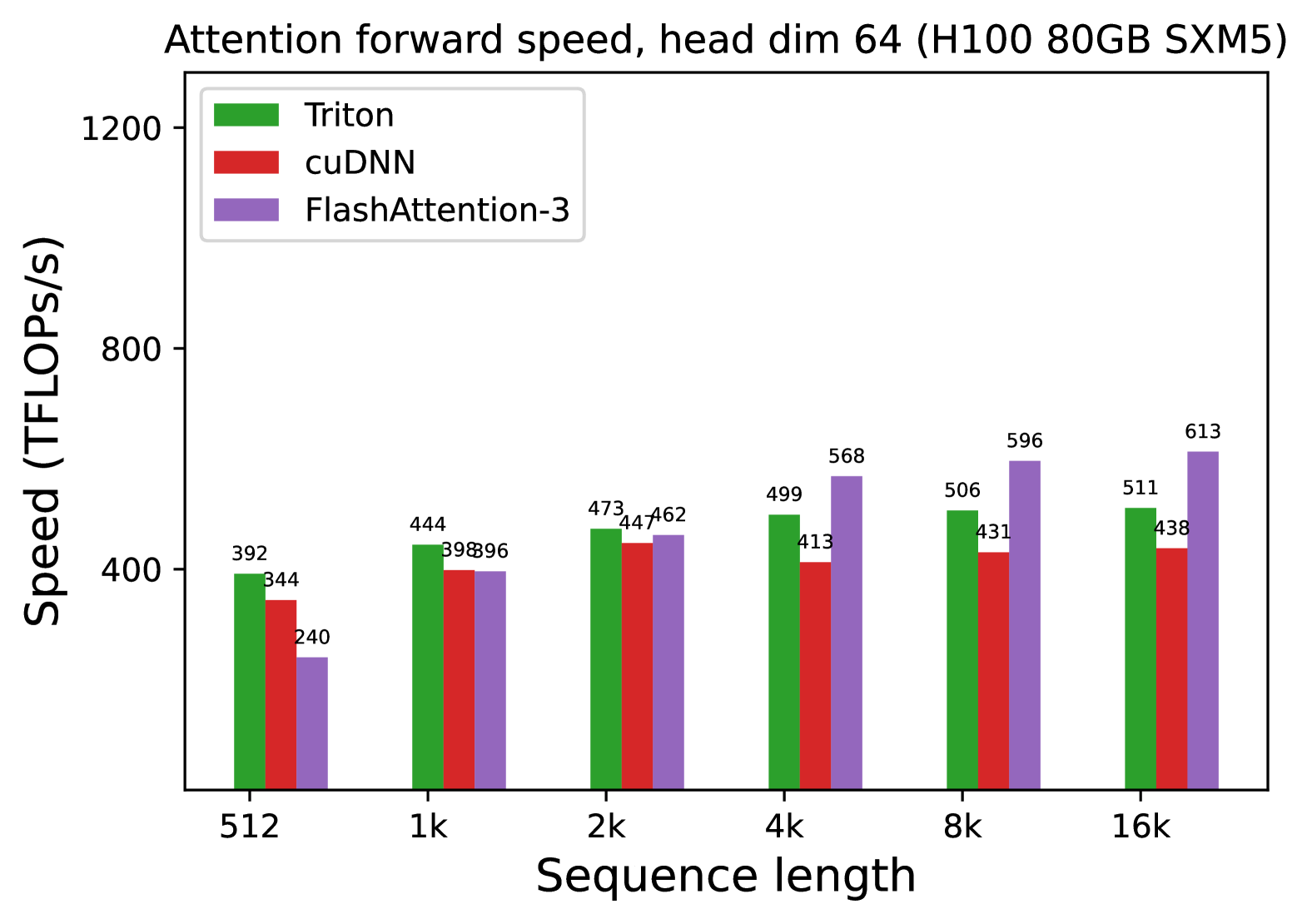
# Technical Document Extraction: Attention Forward Speed Analysis
## Chart Title
**Attention forward speed, head dim 64 (H100 80GB SXM5)**
## Axis Labels
- **X-axis**: Sequence length (categories: 512, 1k, 2k, 4k, 8k, 16k)
- **Y-axis**: Speed (TFLOPs/s)
## Legend
| Model | Color |
|---------------------|--------|
| Triton | Green |
| cuDNN | Red |
| FlashAttention-3 | Purple |
## Data Points
| Sequence Length | Triton (TFLOPs/s) | cuDNN (TFLOPs/s) | FlashAttention-3 (TFLOPs/s) |
|-----------------|-------------------|------------------|-----------------------------|
| 512 | 392 | 344 | 240 |
| 1k | 444 | 398 | 396 |
| 2k | 473 | 447 | 462 |
| 4k | 499 | 413 | 568 |
| 8k | 506 | 431 | 596 |
| 16k | 511 | 438 | 613 |
## Key Observations
1. **Performance Trends**:
- Triton consistently outperforms cuDNN across all sequence lengths.
- FlashAttention-3 shows the highest speed at 4k, 8k, and 16k sequence lengths.
- cuDNN demonstrates the lowest performance at 512 sequence length (240 TFLOPs/s).
2. **Scalability**:
- All models exhibit increased speed with longer sequence lengths.
- FlashAttention-3 achieves the most significant speed gains at 16k (613 TFLOPs/s).
3. **Hardware Context**:
- Benchmarked on H100 80GB SXM5 GPU with head dimension 64.