## Bar Chart: Model Accuracy Comparison
### Overview
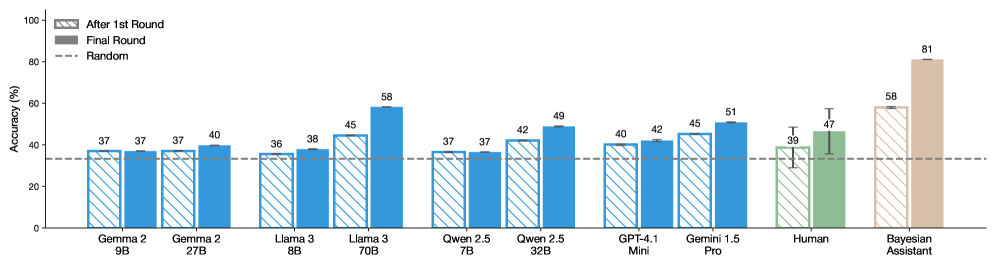
The image is a bar chart comparing the accuracy of various language models, a human, and a Bayesian assistant after one round and after a final round of processing. The y-axis represents accuracy in percentage, and the x-axis lists the different models and the human benchmark. A dashed line indicates a "random" accuracy level.
### Components/Axes
* **Y-axis:** Accuracy (%), ranging from 0 to 100. Increments of 20 are marked (0, 20, 40, 60, 80, 100).
* **X-axis:** Categorical axis listing the models and human benchmark:
* Gemma 2 9B
* Gemma 2 27B
* Llama 3 8B
* Llama 3 70B
* Qwen 2.5 7B
* Qwen 2.5 32B
* GPT-4.1 Mini
* Gemini 1.5 Pro
* Human
* Bayesian Assistant
* **Legend:** Located in the top-left corner:
* "After 1st Round": Represented by bars with diagonal stripes.
* "Final Round": Represented by solid bars.
* "Random": Represented by a dashed horizontal line.
### Detailed Analysis
Here's a breakdown of the accuracy for each model and the human benchmark, comparing the "After 1st Round" and "Final Round" accuracy:
* **Gemma 2 9B:**
* After 1st Round: 37%
* Final Round: 37%
* **Gemma 2 27B:**
* After 1st Round: 37%
* Final Round: 40%
* **Llama 3 8B:**
* After 1st Round: 36%
* Final Round: 38%
* **Llama 3 70B:**
* After 1st Round: 45%
* Final Round: 58%
* **Qwen 2.5 7B:**
* After 1st Round: 37%
* Final Round: 37%
* **Qwen 2.5 32B:**
* After 1st Round: 42%
* Final Round: 49%
* **GPT-4.1 Mini:**
* After 1st Round: 40%
* Final Round: 42%
* **Gemini 1.5 Pro:**
* After 1st Round: 45%
* Final Round: 51%
* **Human:**
* After 1st Round: 39%
* Final Round: 47%
* **Bayesian Assistant:**
* After 1st Round: 58%
* Final Round: 81%
* **Random Accuracy:** Represented by a dashed line at approximately 33%.
### Key Observations
* The Bayesian Assistant shows the highest accuracy in both rounds, with a significant increase from the first to the final round.
* Llama 3 70B and Gemini 1.5 Pro also show notable improvements in accuracy from the first to the final round.
* Some models, like Gemma 2 9B and Qwen 2.5 7B, show no improvement between rounds.
* The human accuracy is relatively low compared to some of the models, especially the Bayesian Assistant.
* All models and the human perform better than random chance.
### Interpretation
The chart suggests that certain language models, particularly the Bayesian Assistant, are significantly more accurate than others. The improvement in accuracy from the first to the final round indicates that some models benefit from additional processing or refinement. The Bayesian Assistant's high accuracy suggests it may employ more sophisticated techniques or have been trained on a more relevant dataset. The human benchmark provides a point of comparison, highlighting the strengths and weaknesses of AI models relative to human performance. The fact that all models perform better than random chance indicates that they possess some level of understanding or pattern recognition.