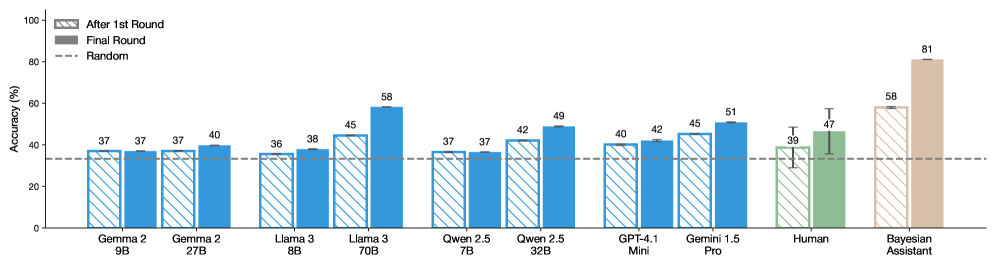
## Bar Chart: Model Accuracy Comparison
### Overview
This bar chart compares the accuracy of several language models (Gemma, Llama, Qwen, GPT, Gemini, Human, and Bayesian Assistant) across two rounds of evaluation: "After 1st Round" and "Final Round". A "Random" accuracy baseline is also provided as a dashed horizontal line. The accuracy is measured in percentage (%).
### Components/Axes
* **X-axis:** Model Name (Gemma 2 9B, Gemma 2 7B, Llama 3 8B, Llama 3 70B, Qwen 2.5 7B, Qwen 2.5 32B, GPT-4.1 Mini, Gemini 1.5 Pro, Human, Bayesian Assistant)
* **Y-axis:** Accuracy (%) - Scale ranges from 0 to 100.
* **Legend:**
* Blue: "After 1st Round"
* Gray: "Final Round"
* Dashed Line: "Random" (approximately at 33%)
### Detailed Analysis
The chart displays accuracy scores for each model in two stages. The "Random" line serves as a baseline for comparison.
* **Gemma 2 9B:** After 1st Round: ~37%. Final Round: ~37%.
* **Gemma 2 7B:** After 1st Round: ~37%. Final Round: ~40%.
* **Llama 3 8B:** After 1st Round: ~36%. Final Round: ~38%.
* **Llama 3 70B:** After 1st Round: ~45%. Final Round: ~58%. This model shows the largest increase in accuracy between rounds.
* **Qwen 2.5 7B:** After 1st Round: ~37%. Final Round: ~37%.
* **Qwen 2.5 32B:** After 1st Round: ~42%. Final Round: ~49%.
* **GPT-4.1 Mini:** After 1st Round: ~42%. Final Round: ~42%.
* **Gemini 1.5 Pro:** After 1st Round: ~45%. Final Round: ~51%.
* **Human:** After 1st Round: ~39%. Final Round: ~47%. The "Human" data includes error bars, indicating variability in performance.
* **Bayesian Assistant:** After 1st Round: ~58%. Final Round: ~81%. This model demonstrates the highest accuracy, particularly in the final round. The "Bayesian Assistant" data also includes error bars.
The "After 1st Round" bars are consistently blue, while the "Final Round" bars are gray. The dashed "Random" line is positioned around the 33% mark.
### Key Observations
* **Llama 3 70B** and **Bayesian Assistant** show the most significant improvements in accuracy from the first to the final round.
* **Bayesian Assistant** achieves the highest overall accuracy in the final round (81%).
* Several models (Gemma 2 9B, Gemma 2 7B, Qwen 2.5 7B, GPT-4.1 Mini) show little to no improvement between the first and final rounds.
* The "Human" performance is represented with error bars, suggesting a wider range of accuracy scores.
* All models perform above the "Random" baseline.
### Interpretation
The data suggests that iterative refinement (the "Final Round") can significantly improve the performance of some language models, particularly Llama 3 70B and Bayesian Assistant. The lack of improvement in other models may indicate that they have reached a performance plateau with the given evaluation method or dataset. The high accuracy of the Bayesian Assistant in the final round suggests it benefits substantially from the iterative process. The inclusion of error bars for "Human" performance acknowledges the inherent variability in human judgment. The "Random" baseline provides a crucial point of reference, demonstrating that all models are performing better than chance. The chart highlights the potential for improvement through continued training and refinement of language models, but also suggests that some models may be more amenable to improvement than others. The difference in performance between the models could be due to differences in architecture, training data, or optimization techniques.