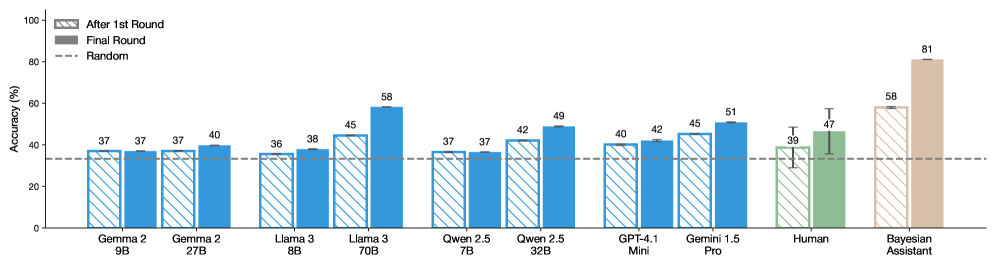
## Bar Chart: Model Accuracy Comparison Across Rounds
### Overview
The chart compares the accuracy percentages of various AI models (e.g., Gemma 2, Llama 3, Qwen 2.5, GPT-4.1, Gemini 1.5) and human/Bayesian Assistant performance across two evaluation rounds ("After 1st Round" and "Final Round"). A dashed line at 37% represents a "Random" baseline. Models are grouped by architecture size (e.g., 9B, 27B parameters) or name, with distinct colors for human and Bayesian Assistant.
### Components/Axes
- **X-axis**: Model names (e.g., "Gemma 2 9B," "Llama 3 70B," "Human," "Bayesian Assistant").
- **Y-axis**: Accuracy (%) from 0 to 100.
- **Legend**:
- Striped bars: "After 1st Round" (blue).
- Solid bars: "Final Round" (blue, green, beige).
- Dashed line: "Random" (37% baseline).
- **Colors**:
- Blue for AI models.
- Green for "Human."
- Beige for "Bayesian Assistant."
### Detailed Analysis
1. **Model Performance**:
- **Gemma 2 9B**: 37% (After 1st Round) → 37% (Final Round).
- **Gemma 2 27B**: 37% → 40%.
- **Llama 3 8B**: 36% → 38%.
- **Llama 3 70B**: 45% → 58% (highest improvement).
- **Qwen 2.5 7B**: 37% → 37%.
- **Qwen 2.5 32B**: 42% → 49%.
- **GPT-4.1 Mini**: 40% → 42%.
- **Gemini 1.5 Pro**: 45% → 51%.
- **Human**: 39% → 47%.
- **Bayesian Assistant**: 58% → 81% (highest final accuracy).
2. **Trends**:
- Most models improve from the first to the final round (e.g., Llama 3 70B +13%, Qwen 2.5 32B +7%).
- Human performance shows moderate improvement (+8%).
- Bayesian Assistant outperforms all models in both rounds, with a significant jump (+23%) in the final round.
3. **Random Baseline**:
- The dashed line at 37% indicates that most models (except Llama 3 8B and Qwen 2.5 7B) exceed random guessing even after the first round.
### Key Observations
- **Llama 3 70B** and **Bayesian Assistant** demonstrate the strongest performance, with Bayesian Assistant achieving the highest final accuracy (81%).
- **Human** performance (47%) is mid-range, trailing behind top models like Gemini 1.5 Pro (51%) and Bayesian Assistant.
- **Qwen 2.5 7B** and **Gemma 2 9B** show no improvement between rounds, suggesting potential limitations in scalability or training efficiency.
### Interpretation
The data highlights the impact of iterative refinement on model accuracy, with larger models (e.g., Llama 3 70B) and specialized architectures (Bayesian Assistant) achieving significant gains. The Bayesian Assistant’s 81% final accuracy suggests advanced reasoning capabilities, potentially surpassing human benchmarks. The lack of improvement in smaller models (e.g., Qwen 2.5 7B) may indicate challenges in scaling or task-specific optimization. The "Random" baseline underscores that even initial model performance exceeds chance, emphasizing the importance of iterative training in AI development.